


Le aziende che sviluppano o utilizzano l’intelligenza artificiale e il machine learning dovrebbero cercare di creare modelli eticamente corretti. Modelli che siano alimentati da dataset esenti da preconcetti, e lo stesso vale per l’engine di intelligenza artificiale e gli algoritmi.
Il punto di vista di Ibm su un tema estremamente attuale è bene esposto in un post sul blog di Watson per mano di Trips Reddy, Senior Content Manager di IBM Watson. Il tema è chiaro: offrire un’indicazione netta in merito al modo in cui costruire la fiducia nell’era dell’intelligenza artificiale.
Il punto è capire in che modo le imprese possano creare modelli di apprendimento automatico che siano “fair”. Fair in questo caso è utilizzato non solo nel significato del termine inglese, “equo”, “giusto”. Ma è una vera e propria “chiave” per interpretare il da farsi.
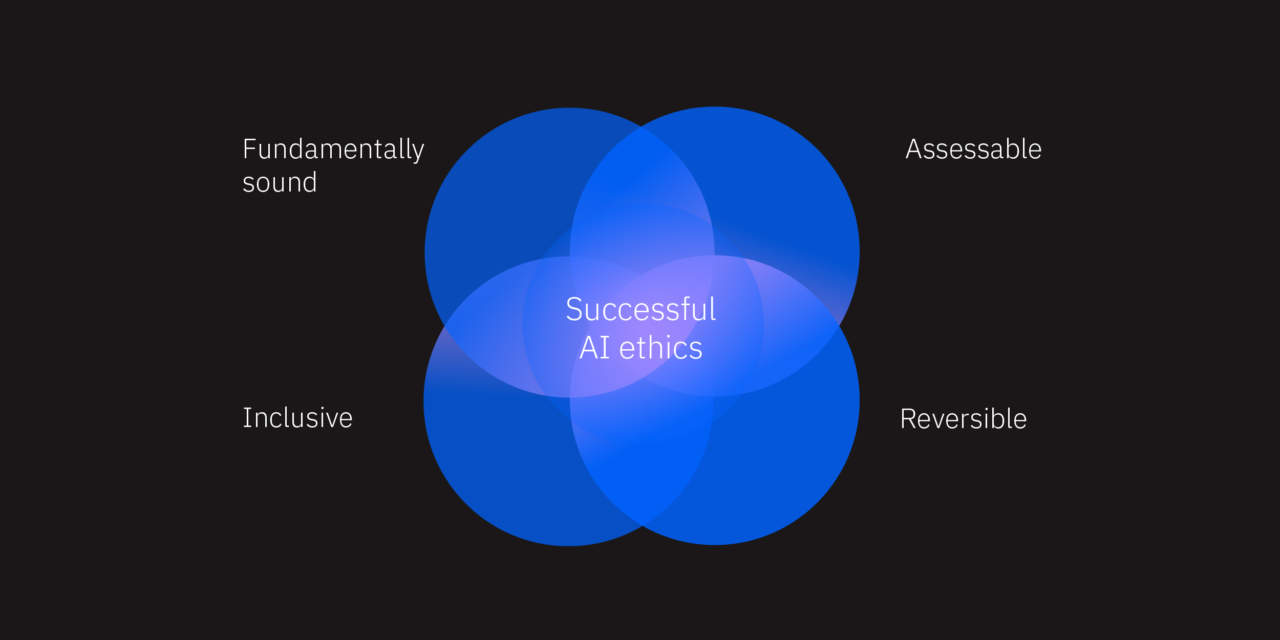
Reddy parte da un recente rapporto di Forrester, The Ethics Of AI: How To Avoid Harmful Bias and Discrimination. Il report descrive i modelli di dati di apprendimento automatico ideali per essere FAIR. Dove FAIR sta per: Fundamentally sound, Assessable, Inclusive, Reversible.
Le aziende dovrebbero sforzarsi di creare modelli “FAIR” per proteggersi da pregiudizi dannosi. Trips Reddy quindi passa a esaminare le raccomandazioni di Forrester su come le organizzazioni possono sfruttare l’intelligenza artificiale per il bene dell’umanità. Evitando allo stesso tempo le insidie etiche associate alla discriminazione percepita.
Per un machine learning etico
 La minaccia di modelli di apprendimento automatico opachi o ingiusti, secondo Ibm, è reale. Gli ambiti safety-critical e altamente regolamentati hanno una maggiore probabilità di avvertirne l’impatto. Le organizzazioni devono essere quindi in grado di verificare e aggiustare modelli “non-fair”. Altrimenti, rischiano di subire conseguenze normative, economiche e sulla reputazione dell’azienda.
La minaccia di modelli di apprendimento automatico opachi o ingiusti, secondo Ibm, è reale. Gli ambiti safety-critical e altamente regolamentati hanno una maggiore probabilità di avvertirne l’impatto. Le organizzazioni devono essere quindi in grado di verificare e aggiustare modelli “non-fair”. Altrimenti, rischiano di subire conseguenze normative, economiche e sulla reputazione dell’azienda.
Le imprese hanno la necessità di costruire modelli che possano guadagnarsi la fiducia delle persone nel tempo. Nel training di un modello AI bisogna anche stare attenti a ogni eventuale ingiustizia presente nei dati sottostanti. Come l’apprendimento umano, anche il machine learning, sottolinea Ibm, è un “prodotto” dell’informazione sorgente, in relazione ai parametri di programmazione.
Istruire un engine di intelligenza artificiale con dati insufficienti o non sufficientemente rappresentativi, farà sì che esso ignorerà ciò che non capirà. Ciò può condurre anche alla discriminazione. Quindi data scientist e sviluppatori devono prevenire qualsiasi tipo di pregiudizio umano o “informatico”. Ma allo stesso tempo sfruttare i meccanismi che possano differenziare tra i clienti, ad esempio per realizzare campagne di marketing profilate.
Ibm, sottolinea Reddy, ritiene di avere l’obbligo di monitorare, e correggere, pregiudizi non etici o deplorevoli negli algoritmi stessi. Così come qualsiasi preconcetto causato da dataset influenzati da persone, con cui i sistemi interagiscono. Watson è trasparente su chi esegue il training dei sistemi AI, quali dati sono stati utilizzati e, soprattutto, cosa guida le raccomandazioni algoritmiche dei clienti.









{kind=link}