


{kind=link}
Non c’è dubbio che negli ultimi anni la tecnologia dei container sia decisamente entrata in una fase di maturità e di adozione sempre più diffusa, non solo come sperimentazione ima anche come implementazioni in ambienti di produzione.
Per meglio comprendere le motivazioni che stanno alla base della loro adozione e gli scenari di utilizzo più adeguati, è importante delineare le principali caratteristiche dei container, e per questo ci siamo avvalsi del supporto di Roberto Pozzi, Data, AI & Automation Technical Sales, Ibm Italia, che ha contribuito con queste interessanti riflessioni.
La prima caratteristica è l’isolamento: un’applicazione con tutte le sue dipendenze è raggruppata in un unico oggetto, il container appunto, semplificandone le procedure di installazione, minimizzando la necessità di riconfigurare e installare prerequisiti e dipendenze, facilitando in sostanza l’installazione, l’esecuzione e la promozione dell’applicazione in diversi ambienti in maniera coerente.
Fondamentale la leggerezza: i container condividono (non virtualizzano) il kernel del sistema operativo sottostante e non necessitano di un sistema operativo completo per ogni applicazione, il che li rende tendenzialmente di dimensioni inferiori rispetto ad una Virtual Machine e più rapidi nei processi di start e stop.
Infine, l’ottimizzazione: le loro caratteristiche peculiari possono consentire un migliore utilizzo delle risorse computazionali dell’infrastruttura sottostante, aprendo inoltre la strada ad una gestione molto più granulare delle risorse assegnate ai singoli containers e favorendo la scalabilità dei sistemi.
Sebbene i containers non siano un costrutto tecnologico nuovo, bensì siano stati incubati ormai per decenni (si può probabilmente tracciarne l’origine dall’introduzione di chroot, quale elemento di isolamento dei processi nei sistemi UNIX alla fine degli anni 70), è la tempesta perfetta degli ultimi 5/10 anni che ne ha decretato il reale successo.
Container, la tempesta perfetta
Come spesso avviene nei cicli di innovazione, sono diversi gli elementi che, nati ed evolutisi parallelamente in contesti eterogenei, concorrono poi a decretare il successo di un determinato paradigma, auto-alimentandosi a vicenda.
Nel caso dei container, sono sostanzialmente due gli elementi principali che hanno contribuito all’affermazione della tecnologia: l’esplosione del modello cloud native e le architetture a microservizi.
Adottare un modello cloud native per lo sviluppo e la gestione delle applicazioni comporta un approccio che sfrutti al meglio le caratteristiche di disponibilità, resilienza e scalabilità delle infrastrutture cloud.
Queste, tra le altre cose, rendono tendenzialmente meno costoso e molto più efficiente affrontare problemi o bug di sistema stoppando e rimuovendo il vecchio servizio (inteso come stack completo di applicazione e infrastruttura), e rilasciando e avviando il nuovo stack, invece che provare a “patchare” il servizio esistente, come è usuale fare in un contesto di applicazioni e infrastrutture tradizionali.
Questo approccio di stop, rimozione e start di uno stack autoconsistente è sorprendentemente in linea con le caratteristiche dei container.

I microservizi sono invece uno stile architetturale che tende a strutturare le applicazioni in servizi indipendenti e disaccoppiati, lungo i confini di specifiche funzionalità di business. Uno stile architetturale non impone un preciso modello implementativo però le caratteristiche di isolamento e indipendenza dei microservizi, nonché la possibilità di scalare in maniera indipendente, insita nel concetto stesso di microservizio, rispondono alle peculiarità dei container.
Disegnare un’applicazione a microservizi non implica necessariamente l’adozione di una piattaforma cloud come veicolo del servizio, così come un microservizio non deve essere necessariamente implementato in un container; è però evidente che le caratteristiche peculiari dei container siano così perfettamente in linea con i principi architetturali dei microservizi e con il modello di fruizione cloud native, da rappresentare oggi la scelta più naturale, efficace ed efficiente per lo sviluppo, l’evoluzione e l’adeguamento delle applicazioni verso i paradigmi architetturali moderni.
Scenari d’uso: edge computing e cloud distribuito
Non c’è uno specifico settore d’industria o un ambito applicativo particolare al quale, a priori, non si possa applicare il paradigma dei container. Tuttavia, esistono alcuni scenari innovativi in cui la containerizzazione delle applicazioni può essere particolarmente utile, quali gli scenari di edge computing e cloud distribuito.
La crescita tumultuosa e l’aumento della potenza di calcolo dei dispositivi sta producendo volumi di dati senza precedenti, destinati a crescere ulteriormente con l’evoluzione delle reti 5G e l’aumento del numero di dispositivi connessi; a questo proposito Gartner stima che entro il 2025 il 75% dei dati verrà prodotto ed elaborato al di fuori dei data center, siano essi tradizionali o cloud.
In questo contesto assumono particolare rilevanza paradigmi tecnologici come l’Edge Computing e il cloud distribuito, che sfruttano proprio la crescente capacità elaborativa disponibile sulla periferia, fornita sia da Edge Servers (veri e propri mini data center distribuiti sul territorio) che Edge Device per raccogliere dati, eseguire analisi predittive e distribuire applicazioni e modelli di intelligenza artificiale esattamente dove i dati vengono generati.
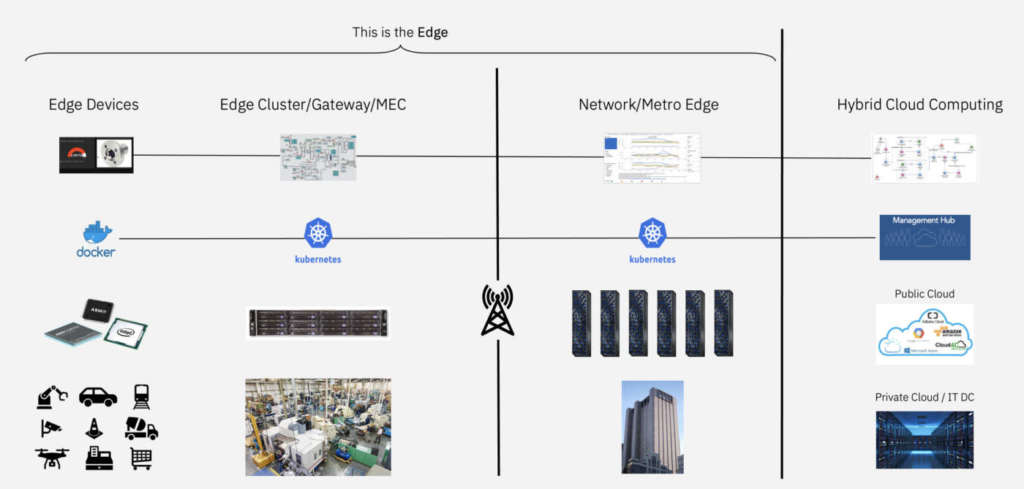
Molteplici sono i settori industriali ai quali si possono applicare tali paradigmi applicativi containerizzati, come l’Healthcare per monitorare i pazienti attraverso device medicali connessi;
Supply Chain, che possono essere efficientate attraverso modelli di Intelligenza Artificiale opportunamente containerizzati in componenti applicative distribuite sull’edge per monitorare ed ottimizzare i processi. Gestione Logistica (es.: portuale, trasporti, …), con l’evoluzione di sistemi di Visual Recognition “on the edge” per migliorare l’identificazione, la localizzazione e la gestione di merci e spedizioni. Tutto questo, se da un lato apre nuovi scenari e possibilità, dall’altro solleva anche nuove problematiche da indirizzare. Ad esempio, come distribuire e controllare le applicazioni sulle edge locations?e ancora, come gestire ed operare in maniera coerente un’infrastruttura così fortemente distribuita, dispersa ed eterogenea?
A queste nuove domande, la tecnologia dei container, unita ad adeguati sistemi gestionali basati sul paradigma architetturale dei microservizi, può fornire risposte interessanti, sfruttando le caratteristiche di isolamento, portabilità e leggerezza dei container per distribuire in maniera coerente applicazioni containerizzate su infrastrutture distribuite ed eterogenee, costituite sia da Edge Servers che da Edge Device, con form factors, risorse e capacità computazionali evidentemente molto diverse; gestire gli aggiornamenti applicativi sull’edge, processo che è decisamente semplificato dalla natura autoconsistente dei container; monitoraggio, stop e restart rapidi dei servizi edge, facilitato ancora una volta dalle caratteristiche di isolamento e “leggerezza” dei containers.
Cloud Satellite è la piattaforma che Ibm ha sviluppato per garantire la flessibilità di poter istanziare, eseguire e controllare servizi cloud containerizzati in qualsiasi ambiente, sia esso on premise, su edge locations o in qualsiasi cloud pubblico, implementando, tramite le tecnologie di orchestrazione dei container, come Red Hat OpenShift, il concetto di Cloud Distribuito, ovvero un punto di controllo e governo di servizi geograficamente distribuiti a partire da una console unica e centralizzata nel Cloud.
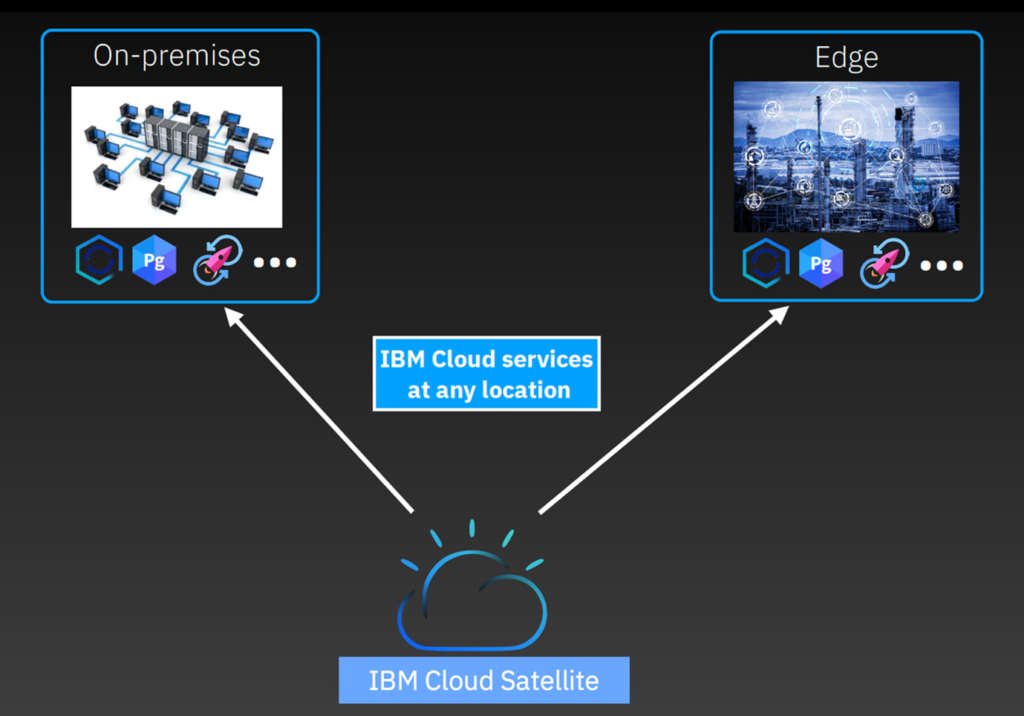
Attraverso questo nuovo livello di standardizzazione della gestione fornito da Ibm Cloud Satellite, le aziende sono quindi meglio equipaggiate per sfruttare i vantaggi di un cloud ibrido e distribuito, che si può così estendere dal cuore del data center tradizionale, ai diversi Public Cloud e fino ai confini più remoti della rete edge.
Un esempio estremamente interessante è la capacità di istanziare e sfruttare, tramite IBIbmM Cloud Satellite, nelle location più opportune (Public Cloud, on-premise oppure Edge), la tecnologia Ibm Cloud Pak for Data. Questa incorpora vari strumenti e framework per implementare le diversi componenti di un’applicazione di Intelligenza Artificiale, dalla raccolta dei dati, alla pulizia e catalogazione degli stessi, all’analisi, fino all’esercizio degli algoritmi di Machine Learning e Deep Learning, utilizzando ancora una volta un’architettura containerizzata.
Manca un ultimo elemento dell’equazione: se attraverso Cloud Satellite è possibile definire e gestire un’architettura di servizi containerizzati geograficamente dispersi sugli Edge Server, come gestire in maniera sicura ed efficiente il deployment di workload applicativi su una topologia potenzialmente costituita da centinaia di migliaia di Edge Device?
La risposta di Ibm a questa problematica è Edge Application Manager una piattaforma intelligente e flessibile, basata su un modello di gestione autonomo che consente di definire policy di deployment, distribuirle sugli Edge Device e fare in modo che siano i device stessi, attivandosi e comunicando con la piattaforma quando la connessione lo consente, a negoziare e ricevere gli aggiornamenti applicativi definiti centralmente in forma containerizzata, sulla base delle loro caratteristiche peculiari.
Le conclusioni di Roberto Pozzi
La tecnologia dei container può essere efficacemente applicata ad un ambito specifico, seppure ampio, come l’Edge Computing e le tecnologie Ibm, sfruttandone le caratteristiche, possono aiutare a creare, distribuire, eseguire, monitorare, mantenere e scalare in modo sicuro ed efficiente applicazioni containerizzate sull’edge, includendo tutto lo spettro di server, gateway e dispositivi, abilitando così nuovi scenari e casi d’uso in particolare, anche se ovviamente non esclusivamente, di Intelligenza Artificiale applicata ai vari processi di business.