


Amazon Elastic Kubernetes Service (EKS) è un servizio Kubernetes di Amazon Web Services, interamente gestito e utilizzato anche da aziende leader in vari settori, per eseguire applicazioni mission critical in quanto a sicurezza, affidabilità e scalabilità.
In particolare, oltre che per altri casi d’uso, Elastic Kubernetes Service, sottolinea Amazon AWS, è rapidamente diventato una delle scelte preferite da parte delle imprese per l’esecuzione dei carichi di lavoro di machine learning.
Ciò, perché il servizio combina l’agilità di sviluppo e la scalabilità di Kubernetes con l’ampia selezione di tipi di istanza Amazon Elastic Compute Cloud (EC2) disponibili su AWS, come le famiglie C5, P3 e G4.
Man mano che i modelli diventano più sofisticati, l’accelerazione hardware è tuttavia sempre più richiesta, per fornire previsioni rapide con un alto throughput.
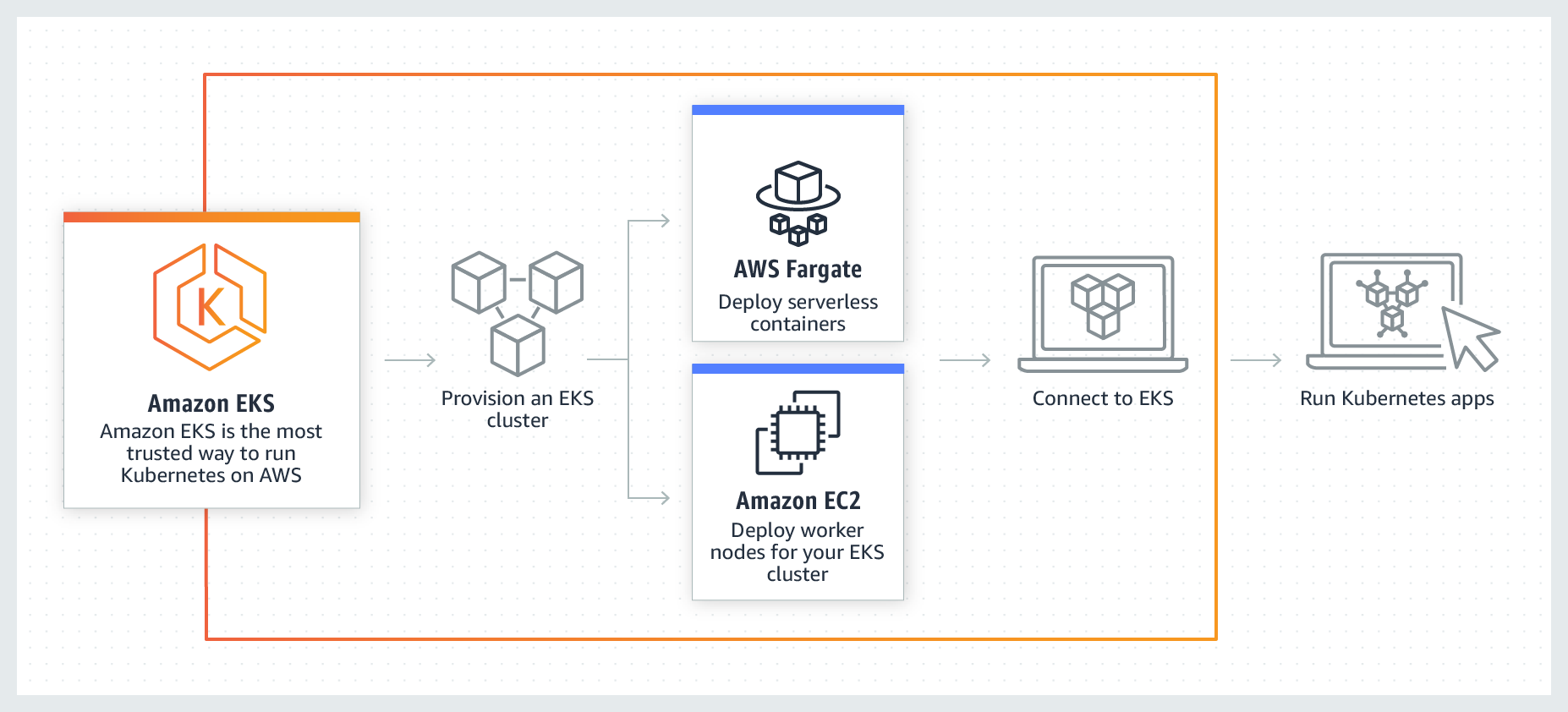
È per questo motivo che il gigante dell’ecommerce e del cloud offre ora la possibilità ai clienti AWS di utilizzare le istanze Inf1 di Amazon EC2 su Amazon Elastic Kubernetes Service, per poter ottenere prestazioni elevate e un costo di previsione più accessibile.
Le istanze Inf1 sono state lanciate da Amazon in occasione di AWS re: Invent 2019: esse sono potenziate da AWS Inferentia, un chip custom creato da AWS in modo specifico per accelerare i carichi di lavoro di inferenza del machine learning.
Le istanze Inf1 sono disponibili in più dimensioni, con 1, 4 o 16 chip Inferentia, con larghezza di banda di rete fino a 100 Gbps e larghezza di banda EBS fino a 19 Gbps.
Un chip AWS Inferentia contiene quattro NeuronCores: ognuno di essi implementa un motore di moltiplicazione di matrici ad array sistolico ad alte prestazioni, che accelera notevolmente le tipiche operazioni di deep learning.
I NeuronCores sono inoltre dotati di una cache di grandi dimensioni su chip, che aiuta a ridurre gli accessi alla memoria esterna, risparmiando così tempo I/O nel processo. Quando su un’istanza Inf1 sono disponibili diversi chip AWS Inferentia, è possibile suddividere in partizioni un modello tra di loro e memorizzarlo interamente nella memoria cache. In alternativa, per fornire previsioni multi-modello da una singola istanza Inf1, è possibile partizionare i NeuronCores di un chip AWS Inferentia su più modelli.
Per eseguire modelli di machine learning su istanze Inf1, è necessario compilarli in una rappresentazione ottimizzata per l’hardware, utilizzando l’AWS Neuron SDK. Tutti gli strumenti sono disponibili sulle AMI di AWS Deep Learning ed è possibile anche installarli nelle proprie istanze.









 ora supporta le istanze Amazon EC2 Inf1 potenziate da AWS Inferentia, chip di inferenza di machine learning){kind=link}