


Dataproc è un servizio completamente gestito di Google Cloud che consente di eseguire in modo facile e veloce i cluster Apache Spark e Hadoop nativi del cloud.
Si tratta di uno strumento particolarmente utile quando la crescita dei dati fa sì che data scientist e ricercatori di machine learning debbano passare da server e laptop personali ad ambienti cluster distribuiti come Apache Spark, engine per l’analisi dei dati su larga scala che offre interfacce Python e R per dati di qualsiasi dimensione.
Grazie a questo servizio gestito, le imprese possono eseguire l’elaborazione dei dati open source su Google Cloud, sfruttando Dataproc come modo agevole e veloce per estendere le attività di data analytics esistenti a dataset dalle dimensioni tipiche “da cloud”.
Con il servizio gestito di Google Cloud, in pratica, i data scientist, per proseguire in modo efficace le loro attività di ricerca, non devono più preoccuparsi della migrazione degli ambienti di dati o di gestire le limitazioni nell’elaborazione associati all’utilizzo dei dati raw.
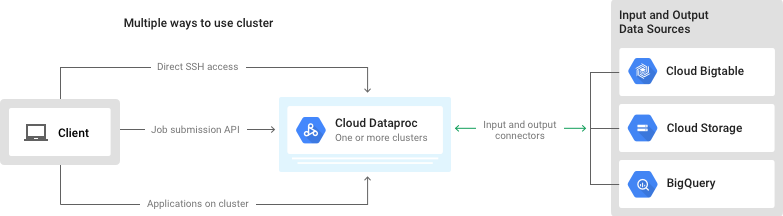
Google Cloud ha di recente annunciato la disponibilità generale di diverse nuove funzionalità di Dataproc, che permetteranno di applicare a set di dati di grandi dimensioni gli strumenti open source, gli algoritmi e i linguaggi di programmazione usati quotidianamente dai data scientist; il tutto, senza dover gestire i cluster e l’infrastruttura It.
Queste nuove funzionalità consentono anche agli analisti di creare sistemi di produzione basati su ambienti di sviluppo personalizzati.
L’autoscaling di Dataproc, la funzionalità di scalabilità automatica dei cluster, automatizza la gestione delle risorse e consente ai data scientist di lavorare nei loro ambienti notebook familiari.
Con la scalabilità automatica di Dataproc, un data scientist può infatti lavorare sul proprio piccolo cluster isolato e personalizzato durante l’esecuzione di statistiche descrittive, la creazione di funzionalità, lo sviluppo di package custom e il test dei vari modelli. Quando è poi pronto per eseguire l’analisi sull’insieme di dati completo, lo può fare all’interno dello stesso cluster e ambiente notebook, se l’autoscaling è abilitato.
Il cluster si espanderà semplicemente alle dimensioni necessarie per elaborare il dataset completo e quindi si ridimensionerà di nuovo al termine dell’elaborazione, senza dover più perdere tempo a spostarsi su un ambiente server più grande o a capire come migrare il lavoro.

L’API Dataproc Jobs consente di inoltrare un job a un cluster Cloud Dataproc esistente, utilizzando l’apposito strumento da riga di comando o dalla Google Cloud Platform Console. Ora, con il rilascio del tipo di job SparkR, è possibile loggare e monitorare i job SparkR, il che semplifica la creazione di strumenti automatizzati attorno al codice R.
L’API Jobs consente a data scientist e analisti di pianificare i job di produzione senza dover impostare nodi gateway o configurazioni di rete. Inoltre, è possibile combinare l’API Dataproc Jobs con il target HTTP di Cloud Scheduler per automatizzare task quali la ri-esecuzione di job per pipeline operative o il re-training di modelli di machine learning a intervalli prestabiliti.
Dataproc, poi, ora offre il supporto per il collegamento di GPU ai cluster. Questa è un’altra funzionalità tesa a unificare l’ambiente di elaborazione per i data scientist e consente agli analisti di risparmiare il tempo e l’impegno di riconfigurare le risorse del cluster sottostante. In un unico template del workflow, è possibile automatizzare una serie di job che abbinano algoritmi di deep learning Spark ML e basati su GPU.
Se, da un lato, utilizzare l’autoscaling per sfruttare più risorse di calcolo è un modo per ottenere le risposte più velocemente, dall’altro, inevitabilmente, ci saranno query e job a lungo termine che rimangono incustoditi: si rischia magari di lanciare un job su un dataset enorme, e tornare a casa per il weekend.
Per assicurarsi di non pagare in eccesso per questi job non presidiati, Google Cloud Dataproc consente di utilizzare l’eliminazione pianificata, per eliminare automaticamente un cluster dopo un periodo di inattività e non dover farsi carico del costo di un cluster non attivo.
Maggiori informazioni su Dataproc sono disponibili sul sito di Google Cloud.









{kind=link}