


Google DeepMind ha annunciato Gemini 1.5, il modello più recente, in grado di offrire prestazioni notevolmente migliorate, secondo l’azienda rivoluzionando la comprensione di contesti complessi attraverso diverse modalità.
Gemini 1.5, afferma Google, offre prestazioni nettamente superiori e rappresenta un cambiamento radicale nell’approccio, basandosi su innovazioni di ricerca e di ingegneria in quasi tutte le parti dello sviluppo e dell’infrastruttura del modello foundation. Realizzato sulla base di una nuova e innovativa versione dell’architettura Mixture-of-Experts (MoE), questo modello risulta più efficiente nell’addestramento e nel funzionamento.
Il primo modello Gemini 1.5 che Google sta rilasciando per i primi test è Gemini 1.5 Pro. Si tratta di un modello multimodale di medie dimensioni, ottimizzato per la scalabilità su un’ampia gamma di compiti e con prestazioni simili a quelle di 1.0 Ultra, il modello più grande di Big G. Inoltre, introduce un’innovativa funzione sperimentale di comprensione dei contesti lunghi.
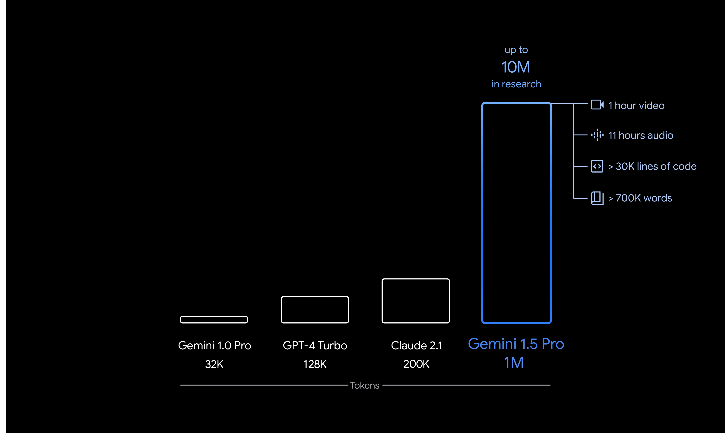
Gemini 1.5 Pro è dotato di una finestra contestuale standard di 128.000 token. Ma, a partire da oggi, un gruppo limitato di sviluppatori e clienti aziendali può provarlo con una finestra di contesto fino a 1 milione di token tramite AI Studio e Vertex AI in anteprima privata.
Di pari passo con il roll-out dell’intera finestra di contesto da 1 milione di token, Google sta lavorando attivamente alle ottimizzazioni per migliorare la latenza, ridurre i requisiti di calcolo e migliorare l’esperienza utente. Secondo l’azienda, questi continui progressi nei suoi modelli di nuova generazione apriranno a persone, sviluppatori e aziende nuove possibilità di creare, scoprire e costruire utilizzando l’intelligenza artificiale.
 Gemini 1.5 si basa sulla ricerca di punta di Google sull’architettura Transformer e MoE. Mentre un Transformer tradizionale funziona come un’unica grande rete neurale, i modelli MoE sono suddivisi in reti neurali “esperte” più piccole.
Gemini 1.5 si basa sulla ricerca di punta di Google sull’architettura Transformer e MoE. Mentre un Transformer tradizionale funziona come un’unica grande rete neurale, i modelli MoE sono suddivisi in reti neurali “esperte” più piccole.
A seconda del tipo di input fornito, i modelli MoE imparano ad attivare selettivamente solo i percorsi esperti più rilevanti della rete neurale. Questa specializzazione aumenta enormemente l’efficienza del modello. Google è stato uno dei primi a adottare e pioniere della tecnica MoE per il deep learning attraverso ricerche come Sparsely-Gated MoE, GShard-Transformer, Switch-Transformer, M4 e altre ancora.
Le ultime innovazioni nell’architettura dei modelli consentono a Gemini 1.5 di apprendere compiti complessi più rapidamente e di mantenere la qualità, oltre a essere più efficiente nell’addestramento e nel servizio. Queste efficienze stanno aiutando i team dell’azienda a iterare, addestrare e fornire versioni più avanzate di Gemini più velocemente che mai, e sono già al lavoro su ulteriori ottimizzazioni.
La “finestra di contesto” di un modello di intelligenza artificiale – sottolinea ancora Google – è costituita da token, che sono i blocchi di costruzione utilizzati per elaborare le informazioni. I token possono essere intere parti o sottosezioni di parole, immagini, video, audio o codice. Quanto più grande è la finestra di contesto di un modello, tanto maggiore è il numero di informazioni che può recepire ed elaborare in un determinato momento, rendendo i suoi risultati più coerenti, pertinenti e utili.
Grazie a una serie di innovazioni nell’ambito dell’apprendimento automatico, Google ha aumentato la capacità della finestra di contesto di 1.5 Pro ben oltre i 32.000 token originari di Gemini 1.0. Ora può gestire fino a 1 milione di token in produzione.
Ciò significa che 1.5 Pro è in grado di elaborare grandi quantità di informazioni in una sola volta, tra cui 1 ora di video, 11 ore di audio, codebase con oltre 30.000 righe di codice o oltre 700.000 parole. Nelle ricerche interne dell’azienda, Google ha anche testato con successo fino a 10 milioni di token.
Gemini 1.5 Pro è in grado di analizzare, classificare e riassumere senza problemi grandi quantità di contenuti all’interno di una determinata richiesta. Ad esempio, quando gli vengono fornite le 402 pagine di trascrizioni della missione dell’Apollo 11 sulla Luna, è in grado di ragionare su conversazioni, eventi e dettagli presenti nel documento.
Oppure, 1.5 Pro è in grado di eseguire compiti di comprensione e ragionamento altamente sofisticati per diverse modalità, compresi i video. Per esempio, quando gli viene dato un film muto di Buster Keaton della durata di 44 minuti, il modello è in grado di analizzare accuratamente i vari punti della trama e gli eventi, e persino di ragionare su piccoli dettagli del film che potrebbero facilmente sfuggire.
Ancora: Gemini 1.5 Pro è in grado di svolgere compiti di problem solving più rilevanti su blocchi di codice più lunghi. Quando gli viene sottoposto un prompt con più di 100.000 righe di codice, è in grado di ragionare meglio sugli esempi, di suggerire modifiche utili e di fornire spiegazioni sul funzionamento delle diverse parti del codice.
Testato su un panel completo di valutazioni di testi, codici, immagini, audio e video, sottolinea Google, Gemini 1.5 Pro supera 1.0 Pro nell’87% dei benchmark utilizzati per lo sviluppo dei modelli linguistici di grandi dimensioni (LLM) dell’azienda. E se confrontato con 1.0 Ultra sugli stessi benchmark, le prestazioni sono sostanzialmente simili.
Gemini 1.5 Pro mantiene alti livelli di prestazioni anche quando la finestra di contesto aumenta. Nella valutazione Needle In A Haystack (NIAH), in cui un piccolo pezzo di testo contenente un fatto o un’affermazione particolare viene inserito di proposito in un lungo blocco di testo, 1.5 Pro ha trovato il testo incorporato il 99% delle volte, in blocchi di dati lunghi fino a 1 milione di token.
Gemini 1.5 Pro mostra anche un’impressionante capacità di “in-context learning“, ovvero è in grado di apprendere una nuova abilità da informazioni fornite in un lungo prompt, senza bisogno di ulteriori messe a punto. Google ha testato questa abilità con il benchmark Machine Translation from One Book (MTOB), che mostra la capacità del modello di apprendere da informazioni mai viste prima. Quando gli è stato dato un manuale di grammatica per il Kalamang, una lingua con meno di 200 parlanti in tutto il mondo, il modello ha imparato a tradurre dall’inglese al Kalamang a un livello simile a quello di una persona che impara dallo stesso contenuto, mette in evidenza la società americana.
Per maggiori dettagli, è possibile consultare il rapporto tecnico di Gemini 1.5 Pro.
In linea con i principi AI dell’azienda e con le sue solide policy di sicurezza, Google si sta assicurando che i suoi modelli siano sottoposti a test etici e di sicurezza approfonditi. L’azienda integra poi gli insegnamenti della ricerca nei suoi processi di governance e di sviluppo e valutazione dei modelli per migliorare continuamente i suoi sistemi AI.
Dall’introduzione della versione 1.0 Ultra a dicembre, afferma Google, i team dell’azienda hanno continuato a perfezionare il modello, rendendolo più sicuro per un rilascio più ampio. Ha anche condotto nuove ricerche sui rischi per la sicurezza e sviluppato tecniche di red-teaming per verificare una serie di potenziali danni.
Prima di rilasciare 1.5 Pro, Google ha adottato lo stesso approccio alla distribuzione responsabile che ha adottato per i suoi modelli Gemini 1.0, conducendo valutazioni approfondite in aree quali la sicurezza dei contenuti e i danni rappresentazionali, e continuerà ad ampliare questi test. Inoltre, sta sviluppando ulteriori test che tengano conto delle nuove capacità di contesto lungo di 1.5 Pro.
A partire da oggi, è disponibile un’anteprima limitata della 1.5 Pro per gli sviluppatori e i clienti enterprise tramite AI Studio e Vertex AI. Google introdurrà 1.5 Pro con una finestra di contesto standard di 128.000 token quando il modello sarà pronto per un rilascio più ampio. Prossimamente, l’azienda ha in programma di introdurre livelli di prezzo che partono dalla finestra di contesto standard di 128.000 token e scalano fino a 1 milione di token, man mano che il modello viene migliorato.
I primi tester possono provare gratuitamente la finestra di contesto da 1 milione di token durante il periodo di prova, ma devono aspettarsi tempi di latenza più lunghi con questa funzione sperimentale, avverte l’azienda. All’orizzonte ci sono anche miglioramenti significativi della velocità, spiega Google.
Gli sviluppatori interessati a testare la 1.5 Pro possono registrarsi ora in AI Studio, mentre i clienti enterprise possono rivolgersi all’account team di Vertex AI.
Sul sito di Google è possibile saperne di più sulle capacità di Gemini e vedere come funziona.









{kind=link}