


{kind=link}
Google Cloud ha annunciato la disponibilità generale delle VM A2 basate sulle Gpu Nvidia Ampere A100 Tensor Core in Compute Engine.
I nuovi tipi di macchine permetteranno ai clienti di Google Cloud a livello globale di eseguire i loro carichi di lavoro di scale-out e scale-up di machine learning e high performance computing (HPC) basati su Nvidia Cuda in modo più efficiente e a un costo inferiore.
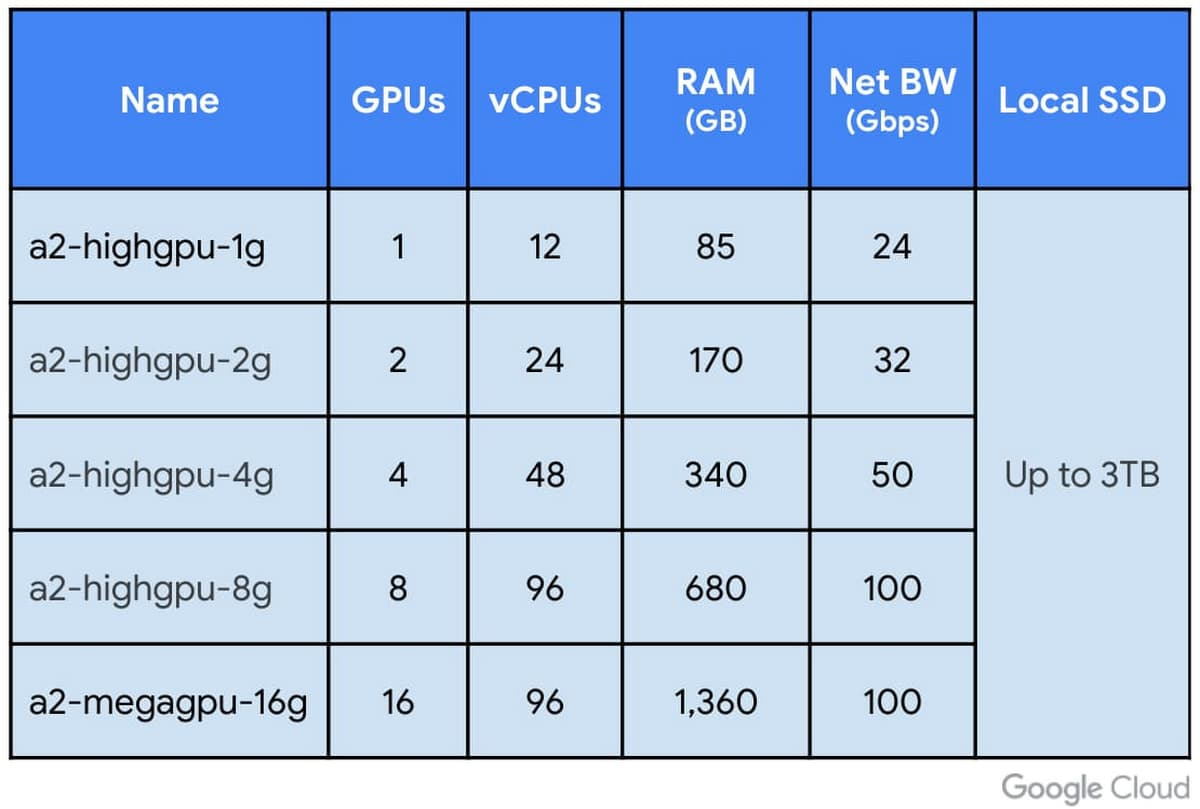
Le VM A2 di Google Cloud si distinguono per l’offerta di 16 Gpu Nvidia A100 in una singola VM e la società di Mountain View le presenta come la più grande istanza Gpu a nodo singolo di qualsiasi cloud provider attualmente sul mercato.
Google Cloud specifica inoltre che la VM A2 permette anche di scegliere configurazioni di Gpu più piccole (1, 2, 4 e 8 Gpu per VM), fornendo la flessibilità e la versatilità necessarie per scalare i carichi di lavoro.
Il fatto che una singola VM A2 supporti fino a 16 Gpu Nvidia A100 facilita gli sforzi di ricercatori, scienziati dei dati e sviluppatori nell’ottenere prestazioni nettamente migliori per i loro workload di calcolo CUDA scalabili, quali il training e l’inferenza per il machine learning e l’HPC.
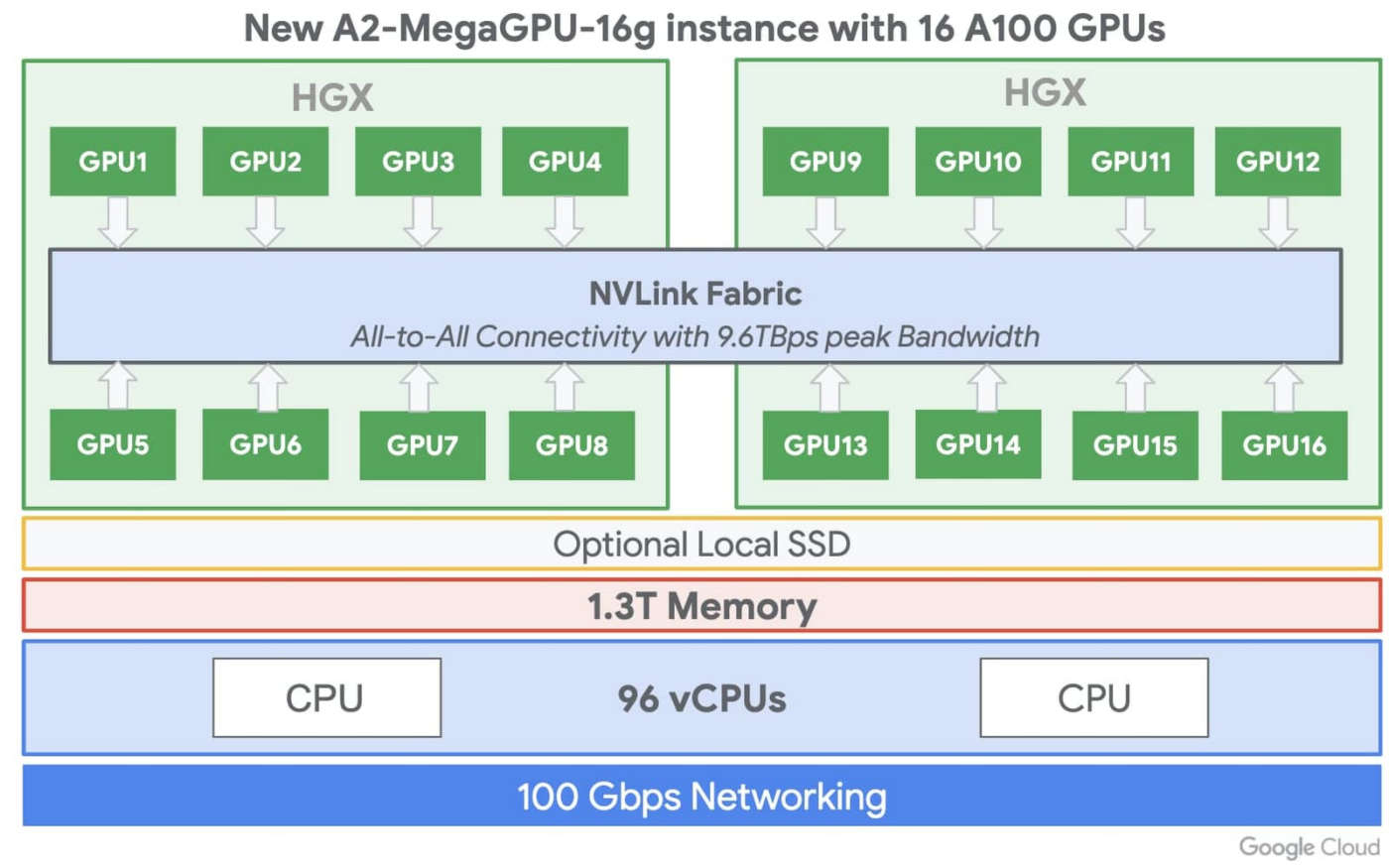
La famiglia VM A2 su Google Cloud Platform, mette in evidenza Big G, è progettata per soddisfare le necessità delle applicazioni HPC attualmente più esigenti, come le simulazioni CFD con Altair ultraFluidX.
Per i clienti che cercano cluster di Gpu di proporzioni ultra-large, Google Cloud supporta cluster di migliaia di Gpu per l’addestramento distribuito di machine learning e librerie NCCL ottimizzate, fornendo le necessarie prestazioni di scale-out.
Le aziende che hanno bisogno di scalare carichi di lavoro ingenti e impegnativi, possono anche iniziare con una Gpu A100 e poi arrivare fino a 16 Gpu senza dover configurare più VM per un training di machine learning a singolo nodo.
Il fatto poi che le VM A2 siano disponibili anche in configurazioni più piccole, offre la flessibilità necessaria per soddisfare le esigenze diverse di applicazioni di vario tipo, con in più la possibilità di associarle a un massimo di 3 TB di SSD locale per fornire i dati alle Gpu in maniera più rapida.
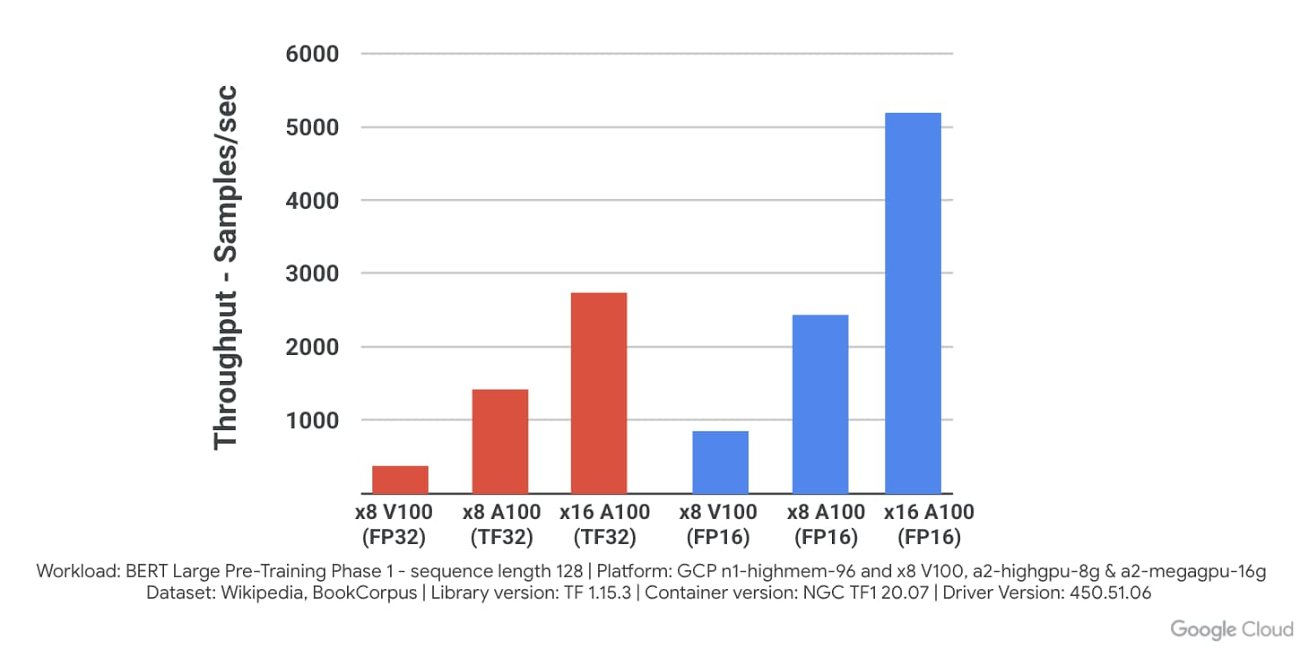
Come risultato, afferma la società di Mountain View, l’esecuzione di A100 su Google Cloud offre un miglioramento delle prestazioni di oltre 10 volte sul modello di pre-training BERT Large rispetto alla generazione precedente di Nvidia V100. Il tutto ottenendo al contempo uno scaling lineare passando da 8 a 16 Gpu.
Inoltre, gli sviluppatori possono sfruttare il software containerizzato e preconfigurato disponibile dal repository NGC di Nvidia per essere rapidamente operativi sulle istanze di Compute Engine A100.