


{kind=link}
Google Research ha presentato Lumiere, un modello di diffusione text-to-video progettato per sintetizzare video che ritraggono un movimento realistico, diversificato e coerente: una sfida fondamentale nella sintesi video, sottolineano i ricercatori.
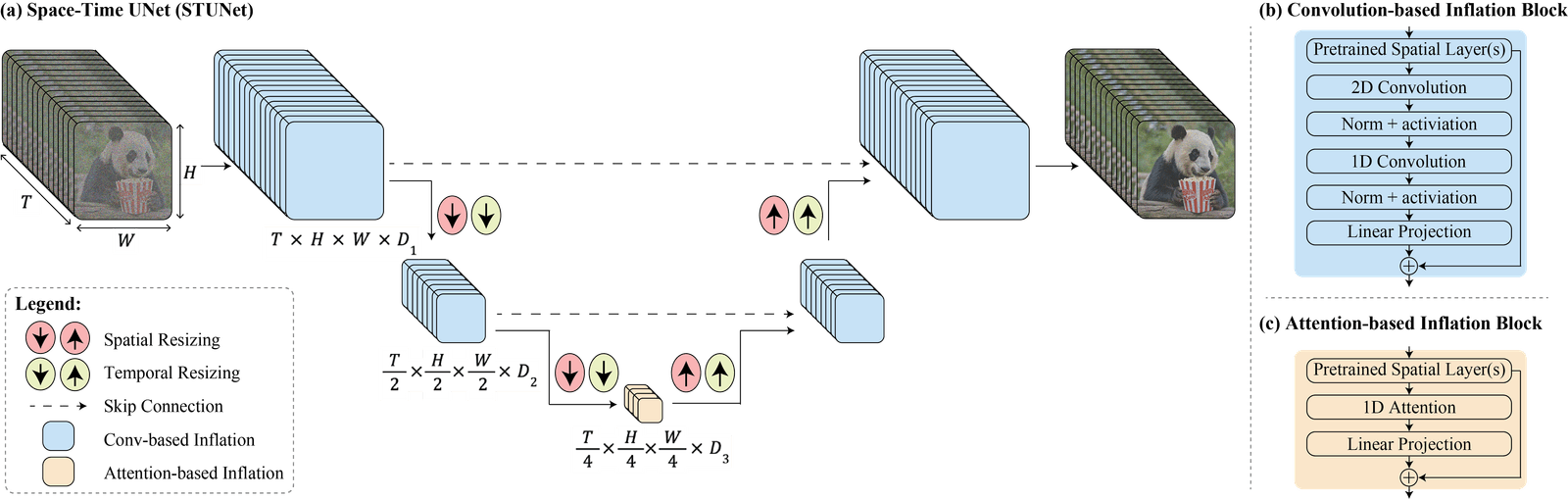
A tal fine, Google ha introdotto un’architettura Space-Time U-Net che genera l’intera durata temporale del video in una sola volta, attraverso un singolo passaggio del modello.
Ciò – spiegano i ricercatori – è in contrasto con i modelli video esistenti che sintetizzano fotogrammi chiave distanti seguiti da una super-risoluzione temporale, un approccio che rende intrinsecamente difficile ottenere una coerenza temporale globale.

Utilizzando sia il down-sampling che l’up-sampling spaziale e temporale e sfruttando un modello di diffusione text-to-image pre-addestrato, il modello di Google Research impara a generare direttamente un video a bassa risoluzione e full-frame-rate elaborandolo su più scale spazio-temporali.
Con il paper su Lumiere, i ricercatori di Google intendono fornire una dimostrazione dei risultati di quella che definiscono una generazione text-to-video allo stato dell’arte e dimostrare come il loro progetto faciliti un’ampia gamma di attività di creazione di contenuti e di applicazioni di editing video, tra cui image-to-video, video inpainting e generazione stilizzata.
Lumiere ha capacità text-to-video, la generazione di video partendo da un prompt testuale, così come image-to-video, genera video partendo da un’immagine e un prompt di testo. Può anche produrre una generazione stilizzata: utilizzando una singola immagine di riferimento, Lumiere è in grado di generare video nello stile desiderato, utilizzando i pesi del modello text-to-image fine-tuned.
Sul sito del progetto è possibile ottenere ulteriori informazioni e visualizzare esempi, nonché scaricare il paper.