


OpenAI ha rilasciato il suo ultimo modello flagship, GPT-4o, che secondo l’azienda offre lo stesso livello di intelligenza di GPT-4 ma aumentando in modo significativo sia la velocità che le capacità nel testo, nell’audio e nelle funzioni di computer vision.
Quest’ultima caratteristica è sottolineata sin dal nome del nuovo modello: la “o” di GPT-4o sta infatti per “omni” e OpenAI definisce il suo nuovo modello come “omnimodel”, che abilita un’interazione molto più naturale e intuitiva tra l’utente e il chatbot. A questo contribuisce il fatto che il nuovo modello accetta come input qualsiasi combinazione di testo, audio e immagine e genera in output una qualunque combinazione di testo, audio e immagine.
Non solo: questo obiettivo viene raggiunto eguagliando il già potente modello GPT-4 Turbo nelle prestazioni su testi in inglese e con codice, e in più – sottolinea OpenAI – con miglioramenti significativi su testi in lingue diverse dall’inglese.
A ciò si aggiunga che – in base a ciò che OpenAI ha condiviso – GPT-4o è molto più veloce e al contempo meno costoso (il 50% in meno, mette in evidenza l’azienda) in termini di API: questo è chiaramente un aspetto di grande importanza per le aziende e gli sviluppatori che stanno costruendo soluzioni basate sull’API di questa AI.
Dicevamo della caratteristica “omni”: il nuovo modello, in particolare, risulta migliore nella comprensione della visione e dell’audio rispetto a quelli esistenti. In un certo senso, GPT-4o è il primo modello che nasce come “omnimodel”. OpenAI ha spiegato di aver addestrato, con GPT-4o, un unico nuovo modello end-to-end per testo, vision e audio, il che significa che tutti gli input e gli output sono elaborati dalla stessa rete neurale.
Secondo OpenAI, poiché GPT-4o è il primo modello dell’azienda che combina tutte queste modalità, siamo ancora alla superficie di queste capacità e c’è ancora molto da esplorare su ciò che il modello può fare e sui suoi limiti.
Per dare un’idea delle prestazioni, GPT-4o è in grado di rispondere agli input audio in appena 232 millisecondi, con una media di 320 millisecondi, che OpenAI definisce un tempo simile a quello di una risposta umana nel corso di una conversazione tra persone. Per fare un paragone, prima di GPT-4o era possibile utilizzare la Voice Mode per parlare con ChatGPT con latenze medie di 2,8 secondi (GPT-3.5) e 5,4 secondi (GPT-4). Prima, per fornire questa funzionalità, veniva utilizzata una pipeline di tre modelli separati: un modello trascrive l’audio in testo, GPT-3.5 o GPT-4 ottengono il testo in input e producono testo in output, e infine un terzo modello converte il testo in audio.
Oltre alla latenza e al decadimento delle prestazioni, questo processo determina anche che la principale fonte di intelligenza, come GPT-4, perda molte informazioni, tra cui ad esempio il tono della voce, o persone multiple che parlano o i rumori di fondo. E, d’altro canto, l’AI non può produrre una serie di sfumature, nemmeno in output. Questi limiti possono essere superati con GPT-4o, perché il nuovo modello “ragiona” su testo, audio e vision in modo integrato.
Alla luce di tutto questo, quando viene misurato su benchmark tradizionali, GPT-4o è in grado di raggiungere prestazioni di livello GPT-4 Turbo per quanto riguarda l’intelligenza testuale, il ragionamento e il codice, e in più stabilisce nuovi ed elevati parametri per quanto riguarda le capacità multilingue, audio e di computer vision.
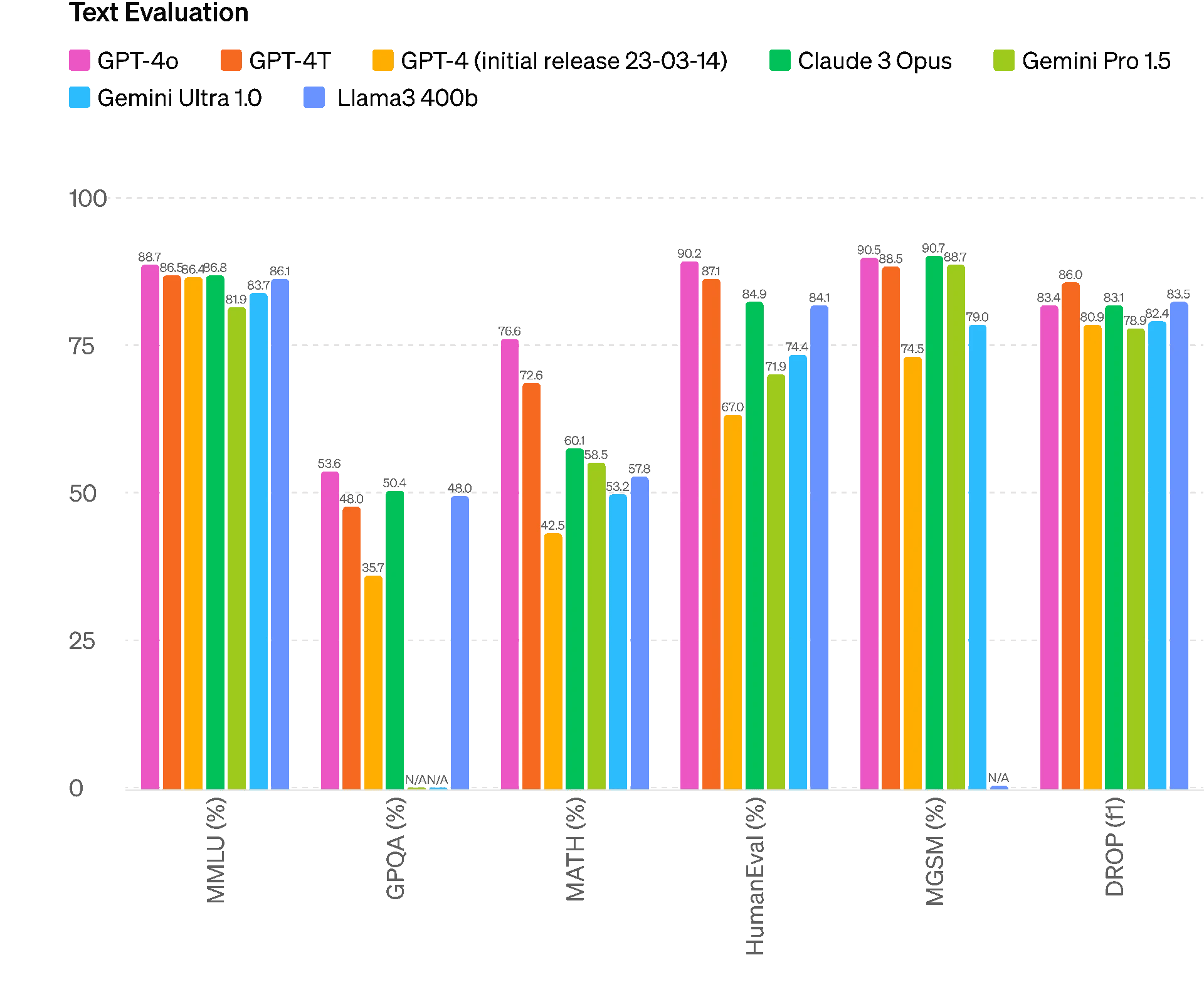 OpenAI ha pubblicato una serie di benchmark eseguiti internamente che mettono a confronto le prestazioni del nuovo modello sia rispetto agli altri dell’azienda, sia rispetto a modelli di altre aziende.
OpenAI ha pubblicato una serie di benchmark eseguiti internamente che mettono a confronto le prestazioni del nuovo modello sia rispetto agli altri dell’azienda, sia rispetto a modelli di altre aziende.
La tokenizzazione del linguaggio (Language Tokenization) in un modello linguistico di grandi dimensioni (LLM, Large Language Model) è il processo di suddivisione del testo in unità più piccole chiamate “token”, che possono essere parole, parti di parole, caratteri o simboli. Si tratta di un passaggio cruciale nella preparazione del testo per l’input verso gli LLM, poiché i modelli lavorano con sequenze di token piuttosto che con il testo semplice. La compressione del tokenizer impiega una serie di tecniche e metodi per ridurre la dimensione del vocabolario e migliorare l’efficienza della tokenizzazione ed è un passaggio che può influenzare direttamente le prestazioni, l’efficacia e l’efficienza di un modello linguistico. OpenAI ha illustrato una serie di esempi in varie lingue sulla nuova compressione del tokenizer utilizzata, per illustrare la maggiore efficienza del nuovo modello GPT-4o.
È per tutta questa serie di motivi che OpenAI ritiene che GPT-4o possa aprire un nuovo capitolo dell’interazione tra gli utenti e il chatbot AI, in termini di efficienza, efficacia, nonché di naturalezza, intuitività e facilità di utilizzo.
Inoltre, l’efficienza del modello GPT-4o ha consentito ad OpenAI di poter fornire la potenza dell’intelligenza del livello di GPT-4 anche agli utenti Free, oltre che a quelli dei piani a pagamento. Il rilascio di queste funzionalità, ha annunciato l’azienda, avverrà in modo graduale.
Per gli utenti del piano Free, ChatGPT viene impostato di default su GPT-4o; tuttavia, con un limite al numero di messaggi che si possono inviare utilizzando il nuovo modello. Il limite varia in base all’utilizzo e alla domanda e, quando viene raggiunto, ChatGPT torna a utilizzare GPT-3.5.
 Gli utenti di ChatGPT Free possono selezionare GPT-4o – o un altro dei modelli di OpenAI – in qualsiasi momento dal menu a tendina disponibile nell’angolo in alto a sinistra nella finestra della chat.
Gli utenti di ChatGPT Free possono selezionare GPT-4o – o un altro dei modelli di OpenAI – in qualsiasi momento dal menu a tendina disponibile nell’angolo in alto a sinistra nella finestra della chat.
Inoltre, possono in qualunque momento fare l’upgrade del proprio piano a uno degli abbonamenti a pagamento, tramite il link disponibile nella colonna laterale, in basso.
 Gli utenti che hanno sottoscritto un piano ChatGPT Plus o Team, possono beneficiare di un usage cap più ampio, e hanno la possibilità di commutare tra i vari modelli nello stesso modo.
Gli utenti che hanno sottoscritto un piano ChatGPT Plus o Team, possono beneficiare di un usage cap più ampio, e hanno la possibilità di commutare tra i vari modelli nello stesso modo.
Al momento in cui scriviamo (il 14 maggio 2024) gli utenti Plus possono inviare fino a 80 messaggi ogni 3 ore con GPT-4o e fino a 40 messaggi ogni 3 ore con GPT-4, ma il limite potrebbe ridursi durante le ore di punta. Inoltre, il limite di messaggi di GPT-4 e GPT-4o per un utente in uno spazio di lavoro ChatGPT Team è più alto di quello di ChatGPT Plus.
Per quanto riguarda gli utenti dell’API OpenAI, GPT-4o offre diversi vantaggi rispetto a GPT-4 Turbo: è più economico del 50%; presenta rate limit 5 volte superiori, con fino a 10 milioni di token al minuto; è due volte più veloce; le sue capacità vision sono migliori; e fornisce un supporto migliore per le lingue non inglesi.
Per le informazioni sul pricing e sulle caratteristiche dei diversi piani e dell’API di OpenAI consigliamo di consultare la documentazione di ChatGPT, per informazioni dettagliate e aggiornate.









{kind=link}