


{kind=link}
La tecnologia circostante i Big Data sta creando un nuovo ecosistema. Se l’IoT avrà l’impatto quantitativamente maggiore, e se non si può più prescindere dal cloud, altri approcci pongono sfide importanti, quali il già forte NoSql e l’avveniristico data Lake.
Vediamo questi elementi in una veloce rassegna.
I Big Data spingono la nuvola
L’adozione del paradigma cloud è sempre più forte per tutti i livelli. I Big Data lo stanno spingendo ancora più in alto. Già nel 2013 i ricavi del public cloud s’erano impennati, non solo per la forza mostrata da Amazon e Google, ma anche per l’inserimento di mostri dei database, che stanno continuando ad investire in implementazioni potenti quali Cloudera (Intel, Qualcomm, Google) e HartonWorks (Microsoft, Sap, Hp e Teradata).
Quanto l’adozione del cloud possa avvicinarsi al 100%, oppure in che mix di privata/pubblica/dedicata/ibrida ricada la singola implementazione, sono solo parametri d’un contratto. Difficilmente la nuvola avrà spazi ridotti nelle nuove architetture Ict, comprese quelle necessarie all’impiego dei big data.
L’Internet delle cose spinge Big Data e cloud
Oggi tutto quanto di innovativo viene prodotto, dalle lampadine alle automobile, raccoglie e potenzialmente mette a disposizione quantità enormi di dati che possono migliorare la qualità della vita. Ciascun dispositivo connesso richiede un’infrastruttura di comunicazione, memorizzazione ed analisi, quindi un sistema Big Data perennemente ed alacremente in funzione.
Questo vuol dire che quando internet entra nelle cose, il modello di business prevede comunque un costo fisso aggiuntivo, dedicato allo sfruttamento dei dati.
In alcuni casi i dati e le relative analisi possono essere acquistati e non venduti, o acquisiti gratuitamente, sempre senza esborso da parte dell’utente. In tutti gli altri casi, che sono la maggior parte, il costo è ovviamente a carico dell’utente, che sia compreso nel prezzo del bene o servizio acquisito o che sia esplicitato sotto forma di pagamento periodico.
Data Lake Vs. Data Mart
La crescita dei dati non strutturati e il valore che ha per l’analisi dei Big Data ha richiesto nuovi tipi di sistemi di storage e di calcolo distribuiti. La metafora del “lago” vede i dati confluire dalle sorgenti verso una grande massa; gli utenti possono venire a esaminare le acque, tuffarsi o prelevare campioni, oppure trovare un modo per attingervi con regolarità. I data lake conterranno enormi quantità di dati e saranno accessibili attraverso interfacce basate su file e su web.
Quest’idea risponde ad alcune domande fondamentali su efficacia, gestibilità ed usabilità di enormi quantità di dati. Colossi dei contenuti quali Google e Facebook hanno sviluppato modelli di sfruttamento del lago, ma sono gli early adopters in un settore ancora tutto da immaginare, prima ancora che da costruire. Prima di sviluppare modelli affidabili bisogna affrontare la sicurezza.
Per fare un esempio, si consideri che il costo per la protezione dei dati principali sta esplodendo. La causa va ricercata nella crescita dei rifiuti, ovvero del numero di copie inutili generate per test, sviluppo, protezione e replica. Un database può avere da 50 a 60 copie che sono amministrate da diversi utenti per scopi diversi. Molte copie diventano orfane, e quando è richiesto il recupero dei dati contenuti non è chiaro quale replica dovrebbe essere usata. Il sistema di tracciabilità degli archivi è quindi oggetto di analisi e di crescita.
I data lake stanno trasformando l’analisi dei dati in modo rapido ed irrevocabile, eliminando silos e data mart, riducendo i costi ed abilitando la ricerca in tempo reale o quasi, imprescindibile in un crescente numero di attività.
NoSql batterà Sql
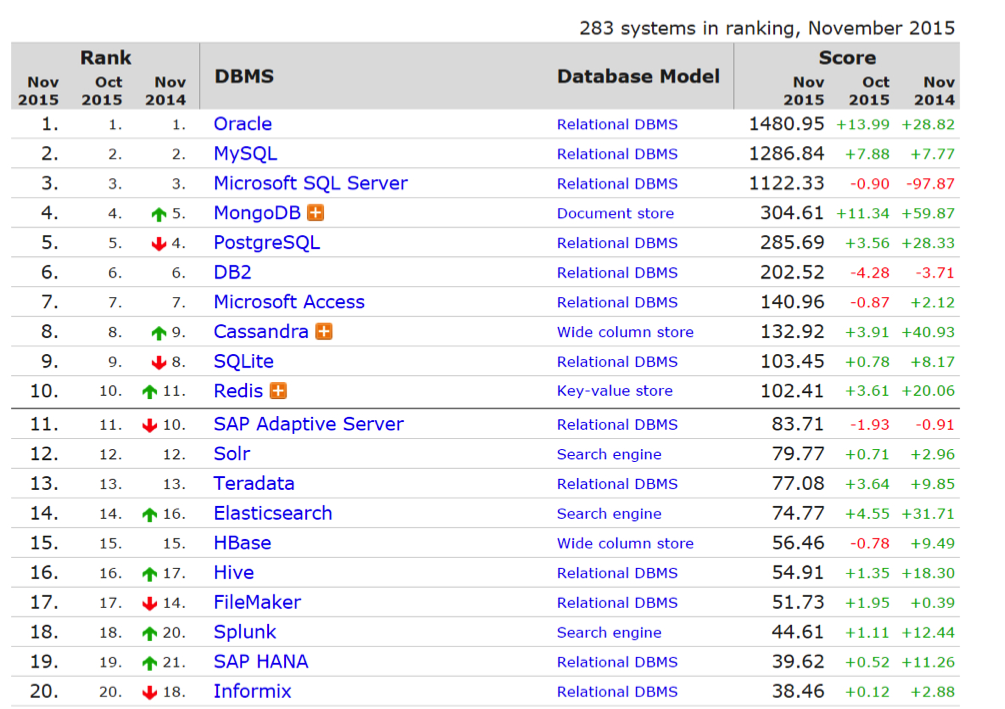
Sql è la chiave di accesso ai database relazionali, mentre il paradigma che gli si oppone, NoSql, non usa costrutti relazionali. Il mercato è al momento ancora nelle mani dei relazionali in generale e di Oracle in particolare, anche se Ibm -una volta tra i leader- sta collassando. Lo scenario più probabile è una giustapposizione dei due modelli, il che sta già avvenendo, con all’orizzonte nuove intriganti questioni.
Anche se ancora non domina, NoSQL sta lasciando un chiaro segno, pensato com’è per rendere elastico, scalabile e flessibile una grande quantità di dati, analizzati più velocemente e anche nel cloud.
Aziende come MongoDB, ma anche Cassandra e Couchbase stanno andando bene, portando innovazione nel mondo Sql, spesso lavorando in settori inattesi. Attenzione anche al settore dei multi-model, dove sono 28mo Amazon DynamoDB e 32mo MarkLogic. La crescita maggiore va all’italiano Orient, oggi 46mo, pilotata da Luca Garulli e Luca Olivari: il primo, intrigante graph database ad entrare nel Magic Quadrant di Gartner fin dal 2013.
Hadoop Vs. Mpp
Una nuova componente della grande architettura di dati in molte aziende è Hadoop, l’infrastruttura distribuita open source sviluppata sotto l’egida della Apache Software Foundation proprio per l’elaborazione di big data.
Difficilmente i database di architettura tradizionale verranno soppiantati integralmente dagli approcci Big Data più o meno aperti, ma è chiaro che Hadoop è vivo e aumenta la sua importanza giorno dopo giorno.
I grandi operatori dei tre mercati di riferimento, ovvero software, hardware e storage, si sono legati ad Hadoop a filo singolo o doppio.
L’ecosistema relativo si sta sviluppando molto velocemente e con investimenti consistenti, rivolti a tutte le fasi del ciclo di vita del dato attivo: memorizzazione, pulizia, integrazione, social media, analisi automatica e di qualità, visualizzazione. Certamente gli investimenti nell’Mpp stanno diminuendo.