


{kind=link}
Ibm ha annunciato CodeFlare, un framework open source progettato per semplificare l’integrazione e la scalabilità efficiente di flussi di lavoro di big data e intelligenza artificiale sul cloud ibrido.
CodeFlare è costruito sulla base di Ray, un framework emergente di calcolo distribuito open source per le applicazioni di machine learning: ne estende le funzionalità aggiungendo elementi specifici per rendere più facile lo scaling dei flussi di lavoro.
In estrema sintesi, CodeFlare semplifica l’integrazione, la scalabilità e l’accelerazione di complesse pipeline multi-step di analytics e machine learning sul multi-cloud ibrido.
Per creare un modello di machine learning oggi, ha messo in evidenza Ibm, i ricercatori e gli sviluppatori devono prima addestrare e ottimizzare il modello. Questo potrebbe comportare la pulizia dei dati, l’estrazione delle caratteristiche e l’ottimizzazione del modello.
CodeFlare semplifica questo processo utilizzando un’interfaccia basata su Python per quella che viene chiamata pipeline, rendendo più semplice l’integrazione, la parallelizzazione e la condivisione dei dati.
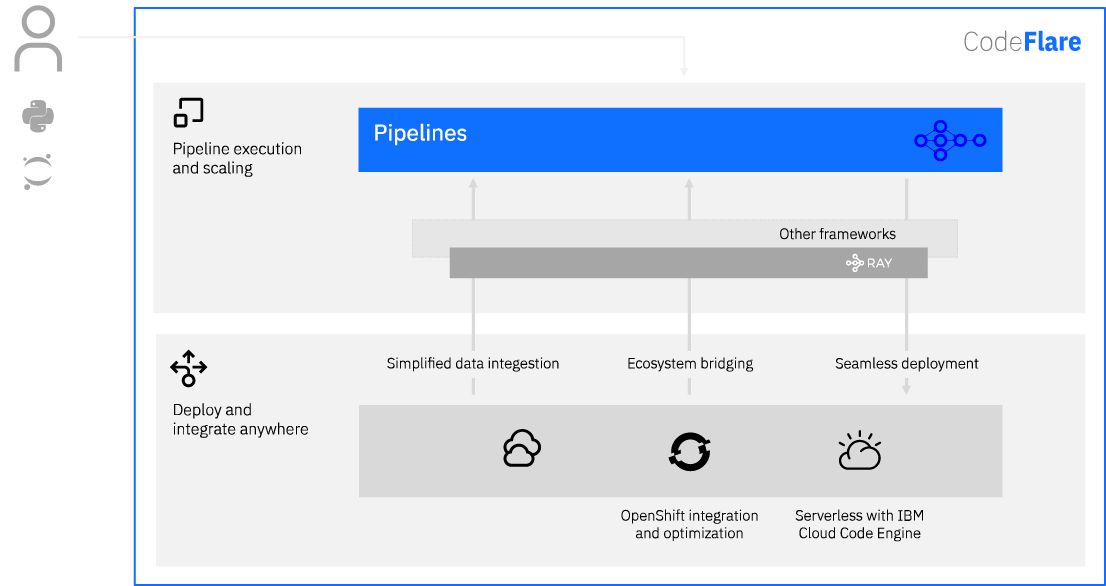
L’obiettivo del nuovo framework, ha affermato Ibm, è quello di unificare i flussi di lavoro della pipeline su più piattaforme senza che sia necessario, per i data scientist, imparare un nuovo linguaggio per il workflow.
CodeFlare, ha poi aggiunto Ibm, dovrebbe anche comportare che gli sviluppatori non debbano duplicare i loro sforzi o faticare per capire cosa hanno fatto i colleghi in passato per far funzionare una certa pipeline.
Con questo framework, Ibm intende fornire agli scienziati dei dati strumenti più ricchi e API che possano utilizzare con più coerenza, permettendo loro di concentrarsi di più sulla loro effettiva ricerca piuttosto che sulla complessità di configurazione e deployment.
Le pipeline CodeFlare vengono eseguite con facilità sulla nuova piattaforma serverless Ibm Cloud Code Engine e Red Hat OpenShift. Gli utenti possono fare il deployment praticamente ovunque, e ciò estende i vantaggi del serverless agli scienziati dei dati e ai ricercatori di intelligenza artificiale.
Il framework rende anche più facile l’integrazione e il bridging con altri ecosistemi cloud-native, fornendo adattatori per event-trigger (come l’arrivo di un nuovo file), così come caricare e partizionare i dati da una vasta gamma di fonti, come gli storage a oggetti cloud, i data lake e i filesystem distribuiti.
CodeFlare, sostiene Ibm, può ridurre drasticamente il tempo per impostare, eseguire, scalare i test di machine learning.