

{kind=link}
Ciao a tutti! Eccoci all’episodio 40 di Le Voci dell’AI.
La settimana scorsa abbiamo visto una serie di esempi di AI applicata nel settore dei trasporti, della difesa e dell’educazione. In quell’occasione vi ho promesso di farvi vedere le cose eccezionali che si possono fare con i nuovi custom GPT di OpenAI.
Rimandiamo l’argomento alla prossima puntata perché oggi preferisco rispondere a due domande che sono arrivate da uno di voi. L’audience ha sempre la precedenza assoluta.
Fabio mi chiede: dato che gli algoritmi di AI oggi presenti sul mercato permettono, tra le varie cose, di sintetizzare la propria voce, come ci si può tutelare? Immagino truffe sempre più efficaci, intercettazioni fittizie e così via. Non esiste una sorta di marchio di firma digitale che possa certificare la veridicità della propria voce?
Bella domanda, Fabio. La risposta è, almeno per il momento: non ci si può tutelare.
Il problema non è tanto garantire che la propria voce sia autentica, quanto piuttosto identificare e bloccare la proliferazione di una voce non autentica e non autorizzata.
A complicare questo problema c’è il fatto che un numero crescente di musicisti e celebrità dello spettacolo ha cominciato a clonare la propria voce e a prestarla per vari progetti commerciali, ricevendo delle royalty come compenso.
Quindi bloccare del tutto la proliferazione di una voce sintetica è una strada non percorribile. Uno scenario possibile potrebbe essere primo identificare quali voci sono sintetiche.
Secondo, verificare quali voci sintetiche sono autorizzate a essere usate per quale progetto.
Per esempio la voce sintetica di Morgan Freeman può essere utilizzata solo nello spot commerciale X e solo per un periodo di un mese.
Perciò qui stiamo parlando di un sistema di Digital Rights Management sofisticato; per renderlo efficace c’è bisogno di un ecosistema di soluzioni software che controllino la presenza di un watermark associato con la voce originale o di un watermark associato con qualunque voce sintetica.
Però, a differenza di quanto promesso da certe start-up senza scrupoli, oggi non esiste una tecnologia di watermarking affidabile, né per gli output digitali come testo e immagini generate, né per voce o per audio sintetici.
Le soluzioni che esistono sul mercato sono facilmente aggirabili e generano un numero significativo di falsi positivi.
Cosa più grave, questi strumenti altamente imprecisi riescono a identificare solo i tentativi di sintesi più maldestri, lasciando liberi di proliferare gli outpost sintetici più sofisticati.
Quindi niente da fare. Per il momento tutto quello che abbiamo a disposizione sono delle nuove leggi contro l’uso di AI generativa per la produzione di output sintetico che ha lo scopo di danneggiare una persona. Ma queste leggi, almeno nel mondo occidentale, come quella inglese di cui abbiamo parlato nell’episodio 34, sono molto limitate.
Per il momento veniamo alla seconda domanda.
Fabio mi chiede anche: che tecnologie vengono utilizzate per testare in termini di performance, bug, security, efficacia i modelli di AI generativa come GPT-4?
Qui la risposta è più complicata.
Ognuna delle dimensioni che Fabio ha indicato richiede un metodo diverso di benchmarking e ogni metodo di benchmarking si avvale di molteplici benchmark che misurano cose diverse.
Cominciamo dal testing di AI in termini della qualità delle risposte, quello che penso Fabio intendesse con la parola efficacia.
In quest’area ci sono una serie di benchmark che la comunità internazionale usa come riferimento.
Ognuno ha un nome complicato da ricordare, come ad esempio HellaSwag, che misura la capacità di un LLM di comporre frasi seguendo lo stesso buonsenso che guida gli esseri umani.
In questo particolare benchmark il modello di AI deve scegliere come completare una frase parziale, scegliendo tra molteplici alternative.
È un test semplicissimo per gli esseri umani, ma non facilissimo per un LLM.
Un altro benchmark molto usato, il GSM8K, che misura la capacità di un LLM di risolvere problemi di matematica di complessità variabile.
Ad oggi praticamente tutti gli LLM prodotti dalla comunità e gli AI sono misurati dalla start- up HuggingFace; i risultati vengono pubblicati in una classifica pubblica che traccia anche il progresso di queste metriche nel tempo.
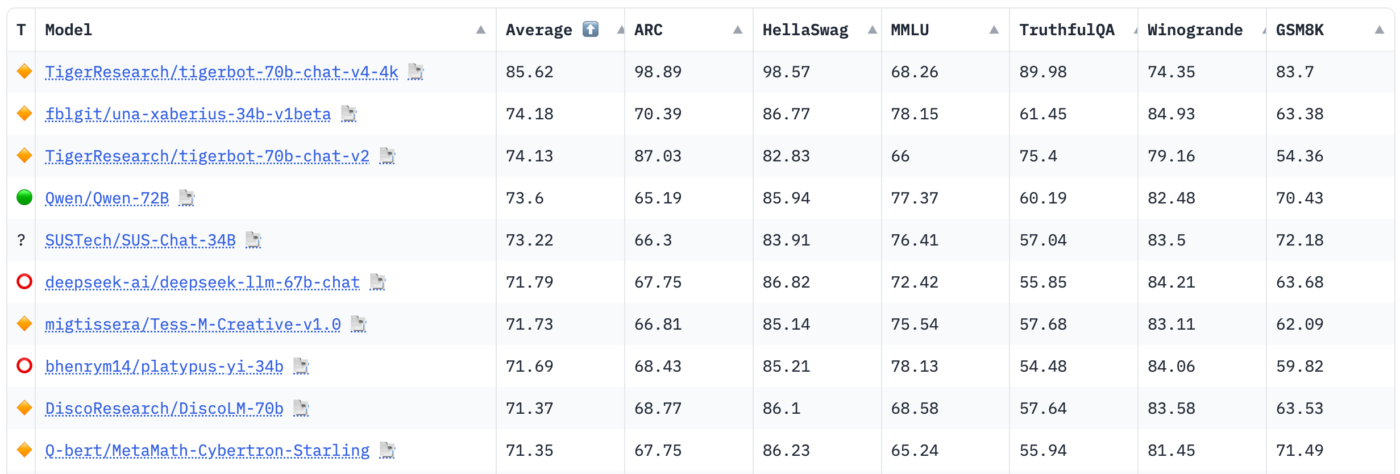
Vedere il proprio modello di AI in cima alla classifica di HuggingFace è motivo di enorme orgoglio per i ricercatori di tutto il mondo e ovviamente, come sempre accade in queste situazioni, in molti cercano di ingannare il sistema, ottimizzando i propri modelli esclusivamente per vincere la competizione.
Oltre a questo, mi preme moltissimo dire che questi benchmark non sempre rappresentano le vere performance di un modello di AI in situazioni reali.
Parte del mio lavoro è testare un numero sterminato di questi modelli, e troppo spesso ho visto delle risposte talmente inaccurate da essere inutilizzabili, generate da modelli in cima a quella classifica.
Ovviamente non sono il solo che ha notato il problema ed è per questo che ogni settimana qualcuno propone un nuovo benchmark più realistico per rimpiazzare o affiancare i sette che abbiamo menzionato prima, ad esempio Google ha recentemente suggerito l’adozione di un nuovo benchmark chiamato IFEval, volto a testare la capacità di un LLM di seguire delle istruzioni precise e verificabili.
Ovviamente, come in qualunque altro settore, dell’IT, ogni fornitore tecnologico cerca di spingere nella direzione dove è più forte, in modo tale che il nuovo benchmark dimostri che la propria soluzione sia buona tanto quanto quella dei competitor o addirittura migliore.
Visto che Google ha perso tutta la sua credibilità nel campo dell’intelligenza artificiale negli ultimi anni, è sempre bene domandarsi se un nuovo benchmark trova effettivamente un punto utile per gli utenti finali o no?
Adesso veniamo alle altre dimensioni che possono essere testate menzionate da Fabio. La situazione si complica moltissimo.
Prendiamo per esempio le performance di un LLM in termini di velocità di inferenza, almeno credo che questo fosse l’intento della domanda.
Di solito la velocità con cui un modello di AI risponde alle richieste dell’utente nel processo che si chiama inferenza, viene misurato in iterazioni al secondo o token al secondo nel mondo dei Large Language Model. Questa misura varia enormemente in base al numero di parametri di un modello all’architettura interna del modello, al processo di quantizzazione a cui è sottoposto e all’hardware che esegue il processo di inferenza.
Il processo di quantizzazione, per esempio, riduce la precisione dei numeri usati per rappresentare i vari pesi nel modello e i pesi del modello sono un sottoinsieme di quella cosa che chiamiamo parametri.
Diventa tutto molto complicato molto velocemente, ma, in parole povere, due Large Language Model, ognuno composto da sette bilioni di parametri, possono produrre una velocità di inferenza parecchio diversa in base alla diversa architettura interna e a tutte le altre dimensioni che abbiamo appena menzionato, quindi i risultati di un benchmark di inferenza producono una matrice di comparazione complicatissima che ha senso produrre solo quando si tratta di comparare le performance di più modelli in uno scenario molto preciso.
Chiudiamo con un commento sulle capacità di testare il livello di sicurezza dei Large Language Model.
Qui siamo in una situazione disastrosa, dove non è nemmeno ancora chiaro quali dimensioni rappresentino la vulnerabilità o meno di un modello di AI a certi attacchi.
Ricordiamo che le risposte di un LLM non sono deterministiche. La stessa domanda produce risposte diverse.
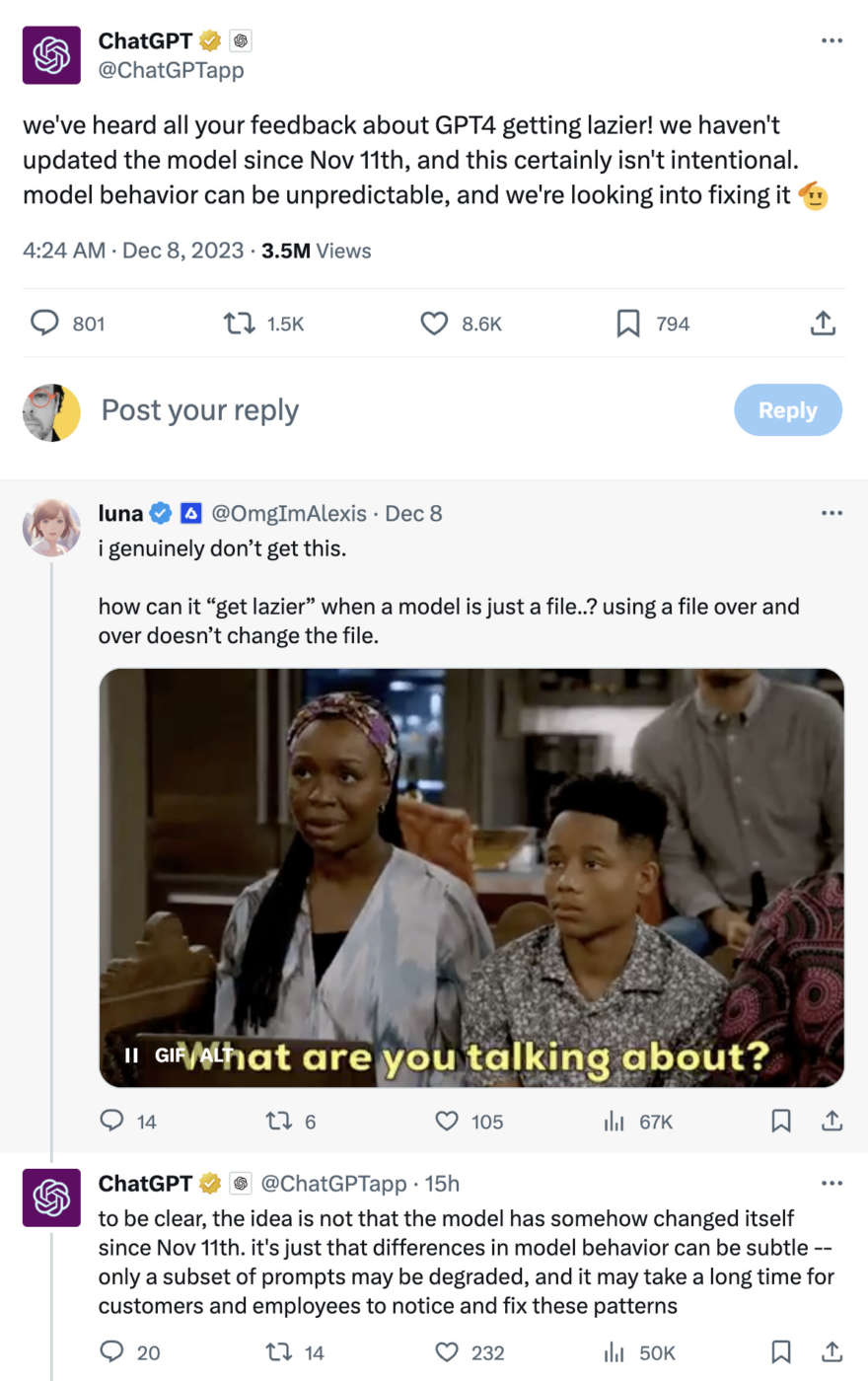 In più ci sono alcuni comportamenti degli LLM che ancora non capiamo, come ad esempio sta succedendo oggi con ChatGTP. Gli utenti lamentano che quel modello è diventato pigro nel rispondere, ma OpenAI giura che non è cambiato niente dall’ultimo rilascio e stanno facendo tutto il possibile per capire cosa sta influenzando il modo di rispondere di GPT-4.
In più ci sono alcuni comportamenti degli LLM che ancora non capiamo, come ad esempio sta succedendo oggi con ChatGTP. Gli utenti lamentano che quel modello è diventato pigro nel rispondere, ma OpenAI giura che non è cambiato niente dall’ultimo rilascio e stanno facendo tutto il possibile per capire cosa sta influenzando il modo di rispondere di GPT-4.
Qualcuno addirittura suggerisce l’ipotesi fantasiosa che il modello cambi atteggiamento a seconda delle stagioni, cercando di replicare il comportamento degli esseri umani. Secondo queste persone d’inverno siamo tutti più pigri.
Se un modello di AI non risponde sempre nella stessa maniera ad un attacco tipo il prompt injection è difficile misurare e comparare.
Infine ricordiamo che anche quando interagiamo con un modello di AI non lo facciamo mai direttamente.
La nostra interazione con un sistema di AI, non un modello, cioè un’infrastruttura complessa, che è stata costruita intorno al modello per migliorarne le capacità o aumentarne la sicurezza.
Questa impalcatura cambia costantemente anche più volte al giorno e quindi è praticamente impossibile misurare il livello di sicurezza di GPT-4 Turbo all’interno di ChatGPT.
Alla meglio potremmo teoricamente misurare il livello di sicurezza di un modello di tipo open access come LLama. Insomma, c’è ancora un sacco di lavoro che dobbiamo fare per arrivare a una batteria di test affidabile e utile, come quelle che esistono per altri tipi di software.
Fabio, spero di averti dato una risposta esauriente anche se non soddisfacente.
Ci fermiamo qui per questa settimana. Come sempre, scrivetemi all’indirizzo di posta elettronica che trovate qui sotto con i vostri commenti, le domande e i suggerimenti per gli argomenti da trattare nei prossimi episodi.
Ciao!