

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore all’Università di Pisa.
Nella puntata di oggi parliamo di Federated Learning, apprendimento federato collegiale, uno specifico paradigma di apprendimento automatico che ci consente di creare un modello predittivo, una soluzione di intelligenza artificiale a partire da dati distribuiti su più dispositivi.
Come funziona questo paradigma e quando ha senso adoperarlo a livello applicativo? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il Federated Learning o apprendimento federato è una tecnica di machine learning che consente di addestrare modelli di intelligenza artificiale utilizzando dati distribuiti, invece di raccogliere e centralizzare i dati in un unico server.
Il modello di intelligenza artificiale viene inviato ai dispositivi locali come smartphone, laptop, qualsiasi dispositivo dell’Internet delle cose, dove viene addestrato direttamente a partire da dati presenti su quel dispositivo e utilizzando le risorse di calcolo dello stesso.
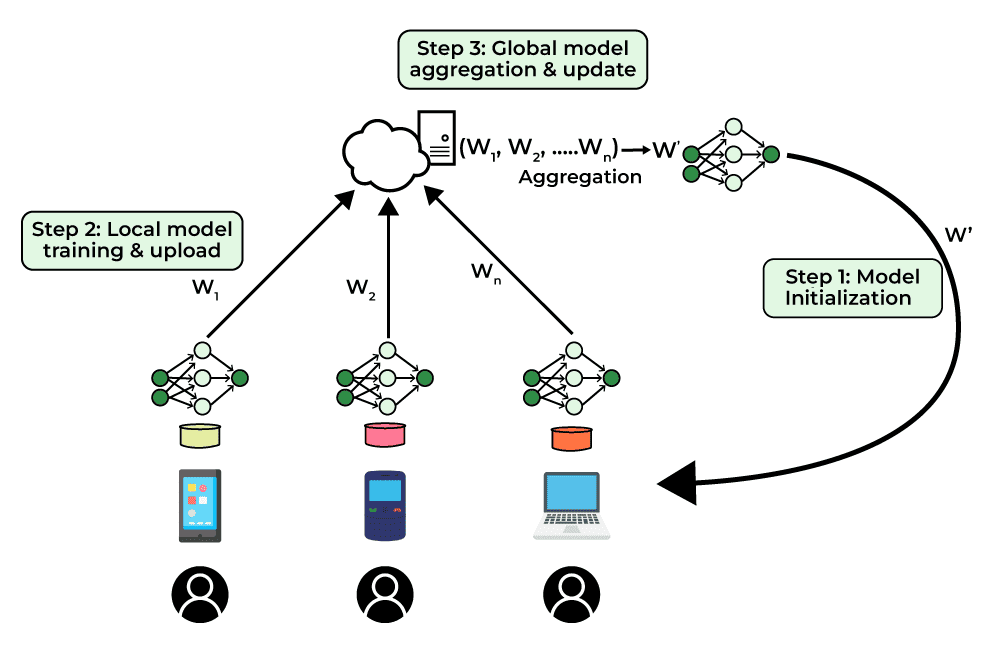
Come vediamo in questa figura, il processo funziona in modo iterativo.
Un modello iniziale viene distribuito ai dispositivi locali che partecipano al collettivo, dove ogni dispositivo lo specializza, lo modifica utilizzando i propri dati e risorse di calcolo, al passo numero uno.
Successivamente, gli aggiornamenti del modello addestrato localmente sui vari dispositivi vengono inviati a un server centrale senza mai inviare i dati originali al passo due.
Il server centrale, infine, aggrega gli aggiornamenti ricevuti da tutti i dispositivi per migliorare il modello globale.
Al punto tre, questo modello aggiornato viene poi ridistribuito ai dispositivi locali per ulteriori cicli di addestramento in maniera continua, iterativa, finché non siamo soddisfatti del risultato o non sono ravvisabili ulteriori migliorie funzionali.
Questa tecnica è particolarmente utile per migliorare la privacy e la sicurezza dei dati, poiché i dati rimangono lungo tutto il processo sui dispositivi locali dove sono stati generati e non vengono trasferiti attraverso la rete.
Inoltre, il Federated Learning riduce la necessità di grandi infrastrutture centralizzate per l’immagazzinamento e l’elaborazione dei dati, rendendolo una soluzione efficiente e scalabile per molte applicazioni di machine learning.
Il Federated Learning è una tecnica relativamente recente nel campo del machine learning, sviluppata per rispondere alla crescente necessità di proteggere la privacy dei dati e degli utenti.
Il concetto è emerso intorno al 2015 grazie al lavoro pionieristico di alcuni ricercatori di Google che cercavano un modo per migliorare i modelli di intelligenza artificiale senza spostare dati privati degli utenti su server centralizzati.
L’idea era di addestrare i modelli direttamente sui dispositivi degli utenti, come smartphone e laptop, raccogliendo solo gli aggiornamenti dei modelli stessi e non i dati grezzi.
Questo approccio ha preso piede rapidamente grazie alla crescente preoccupazione per la privacy dei dati e alla normativa sempre più stringente in materia di protezione dati come il GDPR in Europa.
La prima implementazione pratica del federe learning è avvenuta nei prodotti di Google, come la tastiera virtuale Cyborg, dove il modello di predizione del testo veniva migliorato utilizzando i dati di digitazione degli utenti in modo decentralizzato.
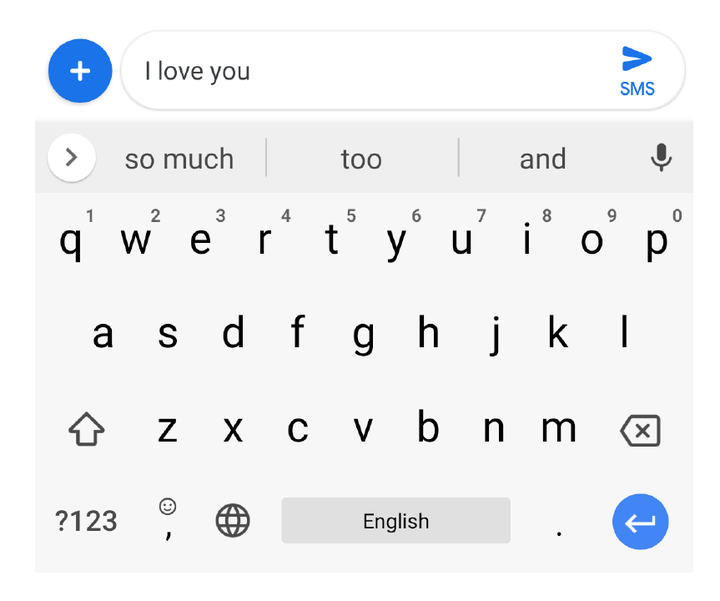
In questa immagine vediamo come, a partire da un input testuale dell’utente che veniva scritto sulla tastiera virtuale “I love you”, la tastiera è in grado di suggerire il completamento del testo match durante le tre sequenze di caratteri ritenute più probabili statisticamente, sulla base di quanto scritto dagli utenti di Cyborg su cui il modello è stato addestrato.
In questo modo è stato possibile offrire un modello predittivo utile a tutti gli utenti, perché velocizza la loro scrittura di messaggi attraverso smartphone, ma lasciando le conversazioni private degli utenti nei loro smartphone senza obbligarle attraverso la rete, esponendoci quindi a un rischio sensibile per la privacy.
Da allora la ricerca sul Federated Learning ha continuato ad espandersi con numerosi studi che esplorano miglioramenti metodologici nelle tecniche di aggregazione dei modelli e la sicurezza dei dati e della gestione delle risorse computazionali.
Oggi il Federated Learning è considerato una delle soluzioni più promettenti per combinare l’efficacia del machine learning con la necessità, d’altro canto, di proteggere la privacy degli utenti e viene adottato in un numero crescente di applicazioni in diversi settori, dalla sanità alle comunicazioni, ai trasporti.
Ma come si relaziona il Federated Learning con l’apprendimento distribuito? Il Federated Learning e il Distributed Learning sono entrambi approcci per l’addestramento di modelli di machine learning in modo distribuito, ma presentano differenze fondamentali.
Il Federated Learning, come abbiamo detto, si concentra sulla privacy dei dati e sull’addestramento locale.
D’altra parte, il Distributed Learning coinvolge la suddivisione del carico di lavoro, dell’addestramento di un modello su più nodi di calcolo che possono essere parte di un unico data center o di un cluster di super computer.
I dati vengono solitamente suddivisi quindi tra i vari nodi esplicitamente che collaborano per addestrare un singolo modello globale.
Esistono due tipi di parallelismo nel Distributed Learning: il parallelismo dei dati e il parallelismo del modello.
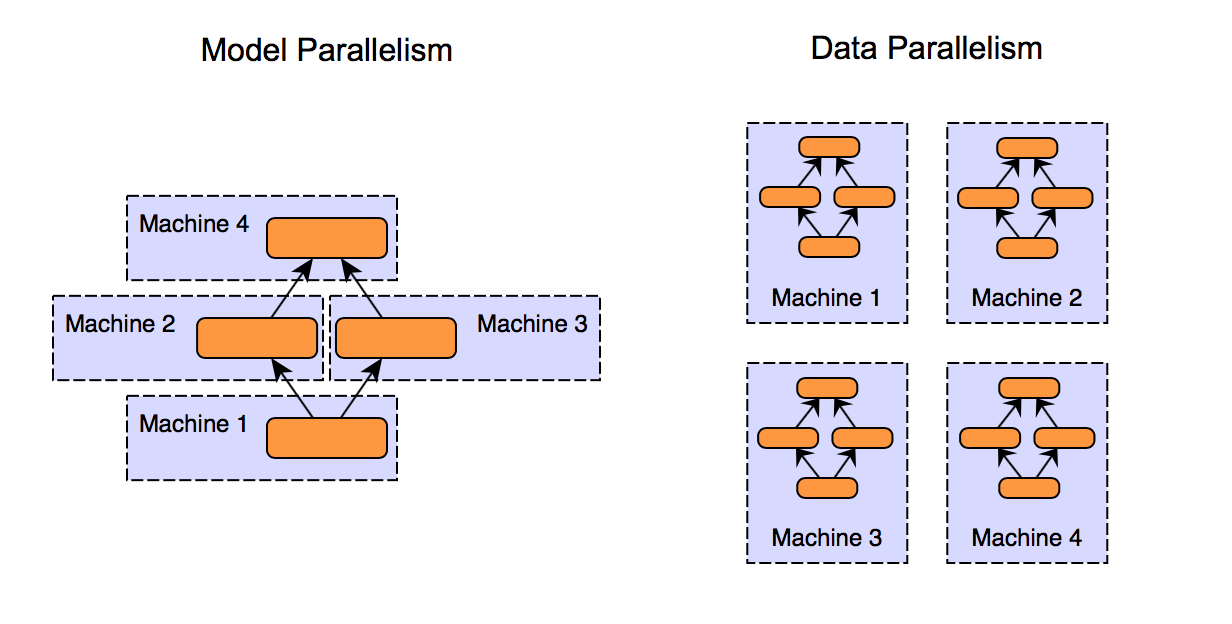
Nel parallelismo dei dati l’intero modello è replicato su ogni nodo, ma ciascun nodo attesta il modello su una diversa porzione di dati.
Nel parallelismo del modello, invece, è il modello stesso a essere suddiviso in parti e ciascun nodo addestra solo una piccola porzione, una parte dell’intero modello, con scambi di informazioni tra i nodi per aggiornare le parti interdipendenti di quest’ultimo.
In sintesi, mentre il Federated Learning punta a mantenere i dati decentralizzati, distribuiti e privati, il Distributed Learning è più focalizzato sull’efficienza computazionale, sulla scalabilità del processo di addestramento, spesso utilizzando dati centralizzati che vengono solo successivamente partizionati proprio per soddisfare l’esigenza di una distribuzione del carico computazionale.
C’è da sottolineare comunque che non è tutto oro quello che luccica: il Federated Learning presenta alcuni limiti significativi sia in termini di privacy sia di efficienza.
Per quanto riguarda la privacy, anche se i dati originali rimangono sui dispositivi locali, ad esempio sui nostri smartphone, gli aggiornamenti del modello possono potenzialmente esporre le informazioni sensibili.
Attacchi abbastanza sofisticati come l’inversione del gradiente possono sfruttare questi aggiornamenti per ricostruire i dati originali.
Il Federated Learning richiede quindi misure di sicurezza aggiuntive per funzionare in maniera efficace, dal punto di vista della privacy, con garanzie superiori come la crittografia e le tecniche di privacy differenziale.
Per mitigare ulteriormente questi rischi interni, invece di efficienza, il segreto del learning può essere limitato dalla variabilità delle risorse computazionali e di memoria dei dispositivi locali.
Non tutti i dispositivi hanno la stessa capacità computazionale, possono essere altamente eterogenei o la stessa disponibilità della rete, il che può portare a dei tempi di addestramento irregolari e prolungati, sbilanciati all’interno della federazione.
Inoltre, la comunicazione tra dispositivi a server centrale può rappresentare un vero e proprio collo di bottiglia, soprattutto con grandi modelli e aggiornamenti molto frequenti, aumentando la latenza ed il consumo di banda.
La gestione delle rigidità dei dati è infine una sfida molto importante per questo paradigma.
I dati sui dispositivi locali possono essere altamente eterogenei, non bilanciati e non rappresentati ivi della popolazione generale.
Quindi della distribuzione di dati che vorremmo modellare del nostro processo di apprendimento, compromettendo la qualità del modello globale a livello funzionale.
Infine, il Federated Learning richiede una robusta infrastruttura centralizzata per coordinare e aggregare gli aggiornamenti, il che può aggiungere ulteriore complessità a livello genetico e costi operativi.
Questi limiti, tutto sommato, rendono necessario un attento bilanciamento tra i benefici che avremo a livello di privacy e l’efficienza operativa.
Per riassumere, in questa puntata abbiamo discusso delle potenzialità del Federated Learning, un nuovo recente paradigma di apprendimento automatico che ci consente di costruire collaborativamente delle soluzioni, a partire da dati distribuiti su una società di dispositivi anche eterogenei.
Una soluzione molto intrigante per migliorare la privacy degli utenti e un primo passo verso una visione forse più collaborativa e decentralizzata dello sviluppo dell’intelligenza artificiale.
Ciao! Alla prossima puntata di Le Voci dell’AI.