

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco ricercatore all’Università di Pisa.
Nella puntata di oggi parliamo di un tema importantissimo per l’intelligenza artificiale moderna e per mitigare i suoi effetti negativi sulla nostra società sempre più digitale.
Imparare a distinguere contenuti generati dall’AI: è possibile farlo? Ci sono dei metodi e strumenti che possiamo utilizzare facilmente.
Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Come abbiamo discusso in moltissime delle puntate precedenti di questa rubrica, l’intelligenza artificiale generativa rappresenta un campo in rapida evoluzione che sta trasformando il modo in cui vengono creati i contenuti multimediali digitali della nostra società moderna.
Recenti tendenze in questo settore includono l’uso di modelli del linguaggio – Large Language Models – come GPT-4 in grado di generare testi coerenti di alta qualità, che spaziano da articoli giornalistici a racconti brevi, da saggi accademici e post sui social media.
Questi modelli sono addestrati su una vasta gamma di dati recuperati dal web, permettendo loro di apprendere le sfumature del linguaggio umano e di replicarle con sorprendente capacità.
Oltre ai testi, l’intelligenza artificiale è generativa è ora capace di creare contenuti multimediali di svariata natura, come immagini, musica e video – lo abbiamo visto in un altro episodio; strumenti come DALL·E possono generare immagini dettagliate a partire da descrizioni testuali, mentre modelli come JukeDeck e OpenAI Jukebox sono in grado di comporre addirittura brani musicali originali.
Nel campo dei video tecnologie emergenti come DeepMind Veo, permettono una generazione di contenuti animati e deep fake, come vengono chiamati, sempre più realistici.
Questi avanzamenti offrono nuove opportunità per la creatività e l’automazione, ma sollevano anche importanti questioni etiche riguardo la proprietà intellettuale, per esempio, e all’uso improprio dei contenuti generati.
Un esempio lampante è rappresentato dalla creazione e diffusione di deep fake, di video manipolati che utilizzano l’intelligenza artificiale per sostituire il volto di una persona con quello di un altro in modo estremamente realistico.
Questi video sono stati utilizzati per diffondere disinformazione politica, creare scandali falsi e compromettere la reputazione di individui innocenti.
Un caso eclatante di deep fake è stato quello del presidente ucraino Volodymyr Zelens’kyj, che appariva in un video fasullo in cui dichiarava la resa durante l’invasione russa del 2022, causando confusione e potenziale destabilizzazione politica.
Inoltre l’AI generativa è stata sfruttata per creare contenuti pornografici non consensuali, dove i volti di persone comuni o celebrità sono stati inseriti in video espliciti senza il loro permesso, violando gravemente la loro privacy e causando possibili traumi psicologici.
Anche la produzione di notizie false, fake news, e campagne di disinformazione su larga scala hanno visto un aumento significativo grazie alla capacità dei modelli di AI di generare testi credibili e coerenti.
Questi esempi, quindi, evidenziano come l’uso improprio dell’intelligenza artificiale generativa possa avere conseguenze devastanti a livello sociale, economico e politico, richiedendo misure urgenti per regolamentare e controllare queste tecnologie.
A questo punto è lecito chiedersi: abbiamo degli strumenti che ci consentano di riconoscere, magari automaticamente, quando questi contenuti digitali, questi artefatti sono effettivamente generati dall’AI? Partiamo dal testo.
Riconoscere automaticamente un testo generato dall’AI è una sfida complessa, ma ci sono diversi metodi e tecnologie emergenti che possono aiutare in questo compito.
Uno degli approcci principali è l’analisi automatica di modelli linguistici e stilistici.
Gli algoritmi in questo contesto possono confrontare il testo sospetto con grandi corpora, ovvero collezioni di testi umani così come generati dall’intelligenza artificiale per individuare peculiarità stilistiche come la frequenza di certe parole, la struttura sintattica e l’uso di frasi o strutture ripetitive.
Uno studio recente della Stanford University ha evidenziato come sia possibile identificare dei contenuti testuali generati dall’AI anche semplicemente analizzando la frequenza di alcune parole.
In questa immagine vediamo come dal lancio di ChatGPT l’uso di certe parole nel web come pivotal, intricate, showcasing e realm sia cresciuto significativamente, quasi esponenzialmente.
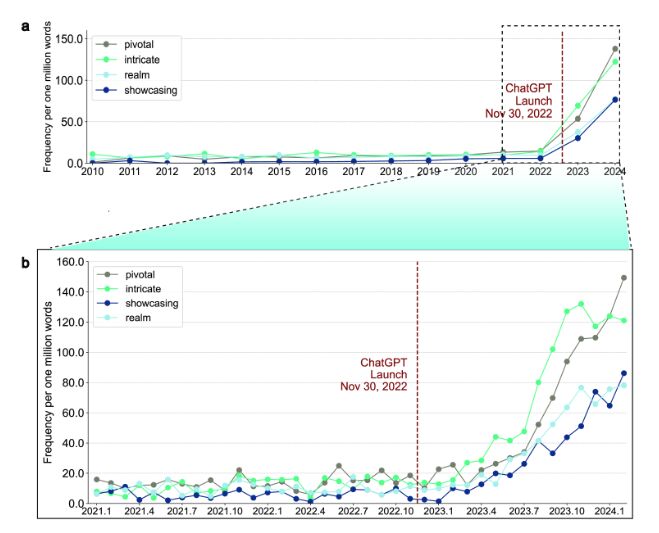
Trovare queste parole nel testo, quindi, coincide con l’aumento della probabilità che questo testo sia generato invece che scritto da un umano.
A parte quindi la frequenza delle parole, tecniche di machine learning, tra cui reti neurali per la classificazione, possono anche essere addestrate specificatamente per riconoscere queste differenze.
Inoltre, strumenti di verifica della coerenza testuale possono identificare eventuali incoerenze logiche o errori semantici comuni nei testi generati automaticamente.
Un altro approccio promettente per il futuro è l’uso di watermark in digitale, dove i testi generati da AI sono contrassegnati con dei segni distintivi non visibili che possono essere rilevati automaticamente, Ma questo tipo di approccio dipende squisitamente dalla buona volontà delle aziende che producono questi sistemi e soluzioni di AI generativa.
In questa immagine vediamo uno strumento liberamente accessibile in rete, GPTZero, che offre un’applicazione web molto semplice per verificare se un testo è stato prodotto da sistemi di AI.
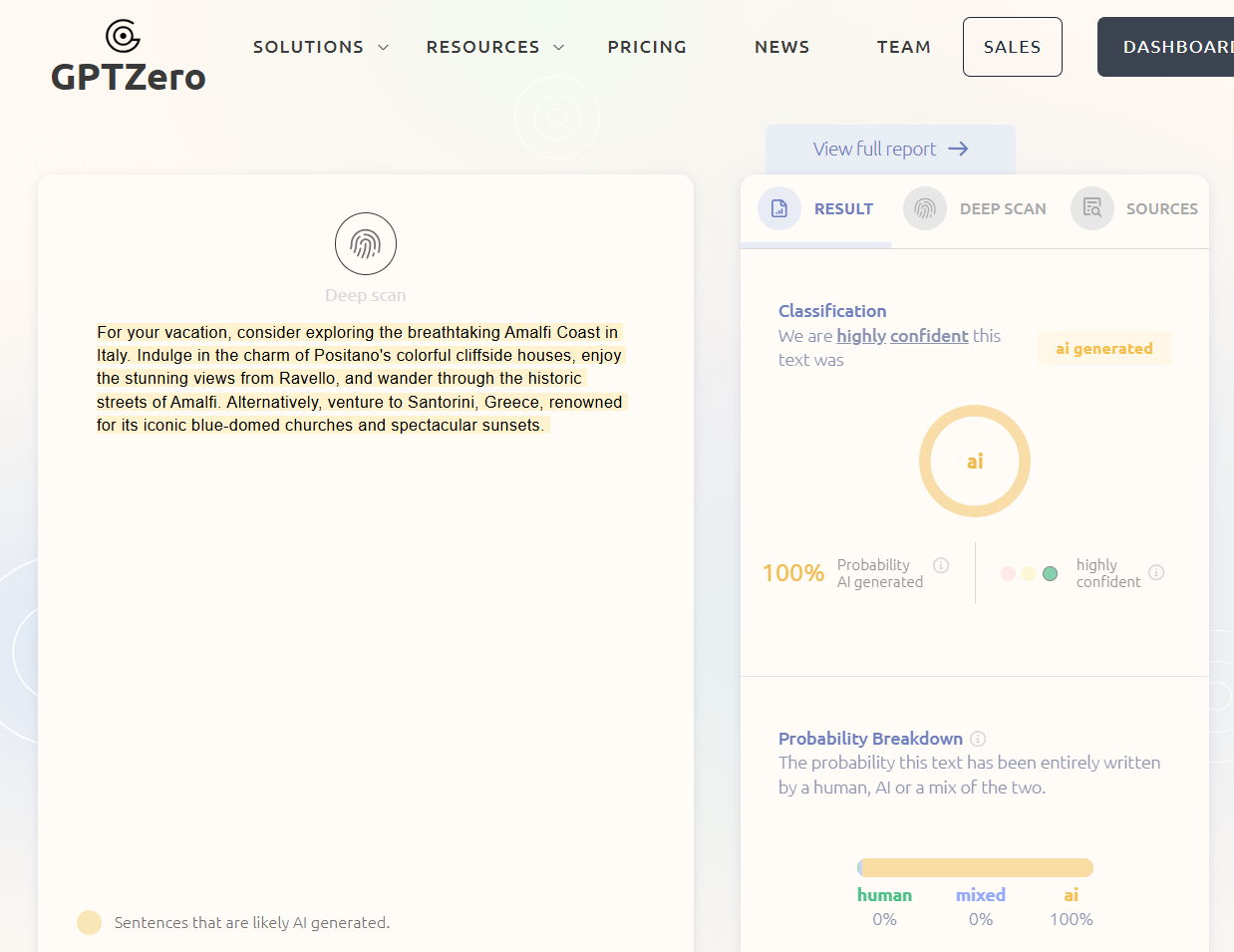
In particolare ho copiato e incollato in questa finestra testuale sulla sinistra un testo che è stato generato da GPT-4, ed effettivamente, come vediamo sulla destra GPTZero riesce a confermarci con una probabilità del 100% che il testo è stato generato da AI.
Ovviamente non possiamo avere garanzie assolute, ma è interessante constatare l’evoluzione di queste metodologie, e degli strumenti automatici a nostro supporto.
Vale la pena anche sottolineare che ad oggi questi strumenti funzionano abbastanza bene per l’inglese, ma sono significativamente meno efficaci su lingue meno comuni, come anche l’italiano.
Approcci simili possono essere utilizzati per immagini e audio, ad esempio, fra applicazioni web con modello freemium, dove è possibile caricare i propri contenuti digitali per ottenere una probabilità di deep fake.
Vediamo come, in questo caso, questa immagine che ho creato con Dall•E sia effettivamente riconosciuta al 99% come generata.
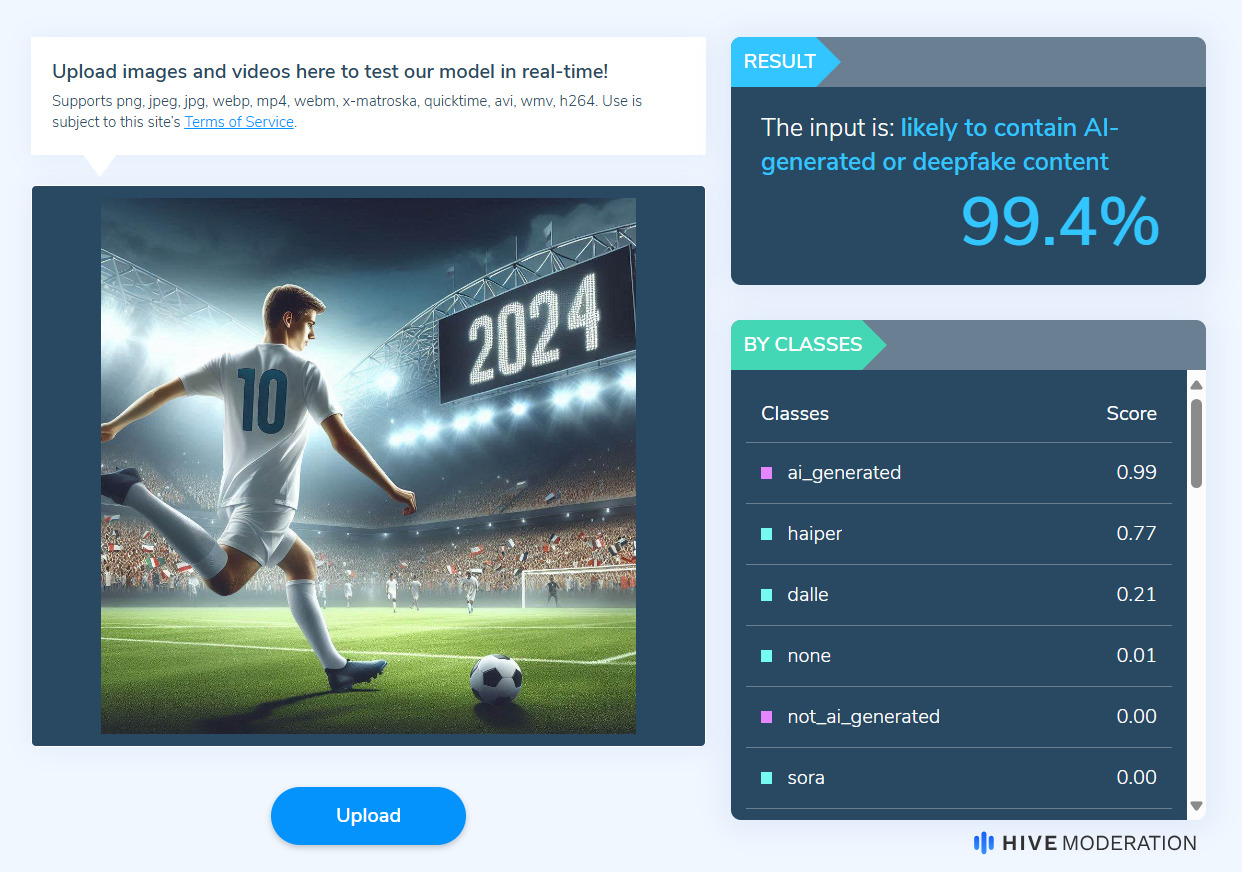
Lo strumento si basa su modelli di machine learning specificatamente addestrati per distinguere contenuti umani da quelli generati automaticamente.
Si tratta quindi di un vero e proprio problema di classificazione dove, data un’immagine, vogliamo predirre l’appartenenza ad una classe di fake o non di fake.
Tutte le varianti di questo approccio si basano dunque su un’ampia collezione di immagini generate da varie soluzioni di immagini reali e generate da umani, che vengono utilizzate come dataset di addestramento.
Proprio come per gli esseri umani, è possibile notare difetti visivi, geometrici, tessiture e strutture visive ricorrenti che evidenzierebbero una generazione automatica.
Va sottolineato come si tratti di soluzioni in evoluzione che devono per forza di cose evolversi continuamente, rincorrendo i cambiamenti introdotti a livello metodologico e applicativo dalle soluzioni di AI generativa che effettivamente producono questi artefatti, questi contenuti digitali.
In questa puntata abbiamo dunque discusso di come è possibile capire in maniera automatica se i contenuti digitali sono stati creati da uomini o da sistemi soluzioni di intelligenza artificiale.
La conclusione è che sì, esistono strumenti accessibili, basati spesso su machine learning, che ci consentono di riconoscere questi artefatti digitali in maniera automatica.
Ma questi ultimi, va riconosciuto, non sono perfetti.
La mia raccomandazione finale è di usare questi strumenti con moderazione, non come una soluzione certa e prioritizzare, come sempre, come i giornalisti sanno bene, l’autorevolezza della fonte.
Ciao! Alla prossima puntata di Le Voci dell’AI.