

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore all’Università di Pisa.
Nella puntata di oggi parliamo finalmente di qualcosa di diverso dai soliti Generative Pretrained Transformers – GPT – e affrontiamo un tema molto interessante, quanto futuristico.
Parliamo di Calcolo neuromorfico e Reservoir computing per l’intelligenza artificiale.
Di cosa si tratta? Qual è lo stato dell’arte in questa direzione? E possibile pensare ad applicazioni realistiche di queste metodologie e tecnologie? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il calcolo neuromorfico è un approccio all’informatica, quindi all’elaborazione automatica di informazioni – per questo: calcolo – ispirato alla struttura e al funzionamento del cervello umano.
Il termine neuromorfico deriva infatti da neuro- che si riferisce a neuroni e -morfico, che significa forma o struttura.
L’obiettivo principale del calcolo neuromorfico è quindi quello di replicare le capacità computazionali del cervello utilizzando circuiti e sistemi elettronici.
Si parla quindi di hardware che imitino il modo in cui i neuroni e le sinapsi funzionano biologicamente a differenza dei tradizionali computer basati sull’architettura di von Neumann che separano la memoria dall’unità di elaborazione.
I sistemi neuromorfici cercano di integrare queste funzioni in modo simile al cervello dei sistemi biologici.
I neuroni, infatti, non operano seguendo istruzioni passo passo su dei dati che vengono spostati appositamente sulla CPU, ma elaborano informazioni in parallelo attraverso connessioni sinaptiche distribuite.
I chip neuromorfici, come quelli sviluppati da IBM – TrueNorth – e Intel – Loihi – cercano di emulare questa architettura facilitando l’elaborazione in parallelo, l’apprendimento autonomo e l’adattamento continuo.
Uno degli aspetti più promettenti del calcolo neuromorfico è la sua efficienza energetica.
I cervelli biologici, pur eseguendo compiti complessi come il riconoscimento visivo, uditivo e decisionale consumano solo una frazione dell’energia necessaria ai super computer moderni.
Pensate che il costo per mantenere acceso e funzionale un cervello umano è paragonabile al consumo di una lampadina da 30 watt! Ebbene, i sistemi neuromorfici mirano a ridurre drasticamente il consumo energetico, rendendoli particolarmente adatti ai compiti come l’intelligenza artificiale integrata, dove la capacità di eseguire calcoli complessi localmente e con risorse limitate è essenziale.
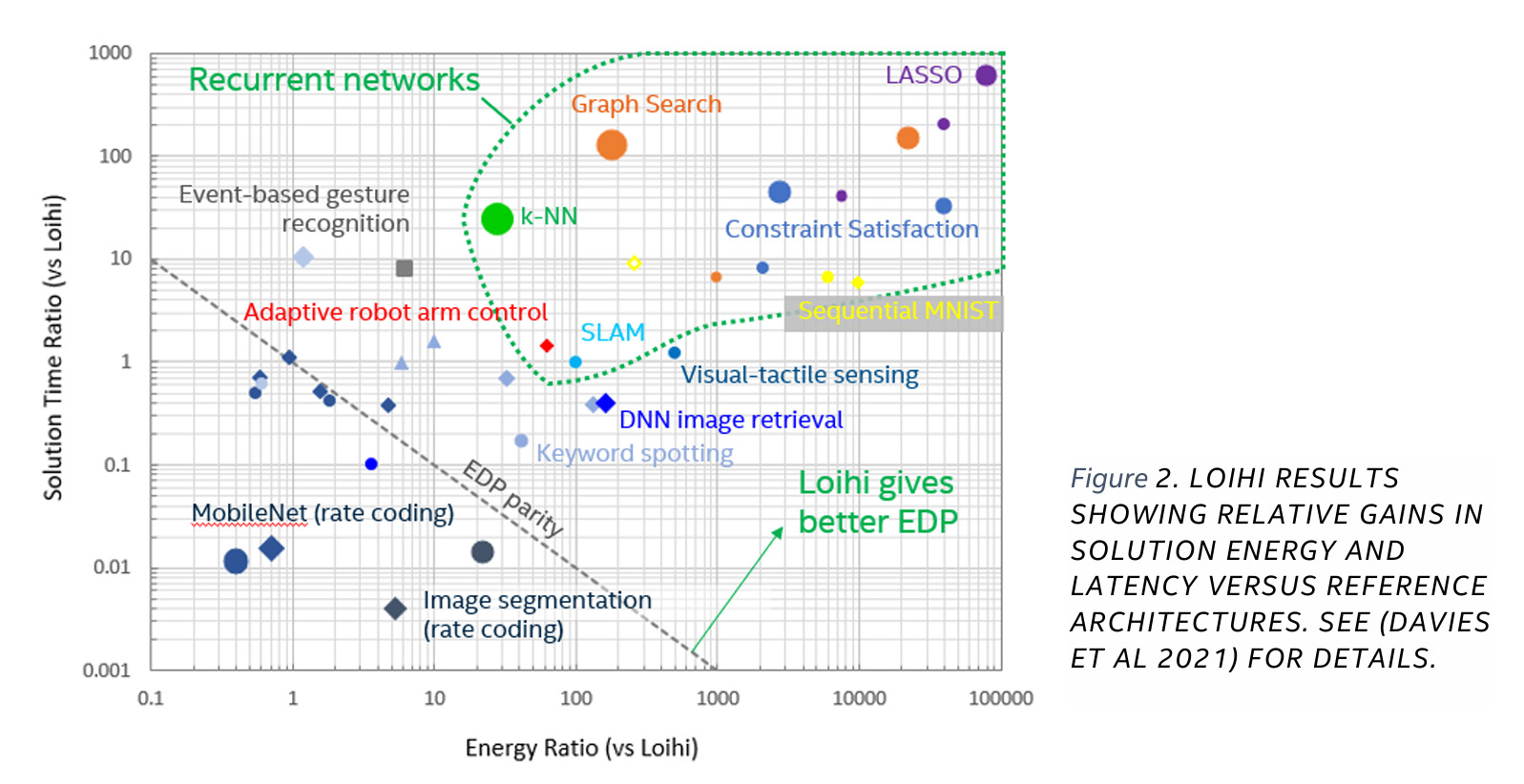
In questa immagine vediamo come diverse architetture hardware si comportano in termini di tempi e energia consumata per risolvere compiti computazionali di natura diversa in relazione al chip neuromorfico Loihi di Intel.
Sulle ordinate abbiamo il tempo, mentre sulle ascisse l’energia, sempre in scala logaritmica.
In particolare con il simbolo quadrato si identifica IBM TrueNorth, chip neuromorfico concorrente, come dicevamo, mentre con il cerchio e il rombo CPU e GPU, rispettivamente.
Come leggere questo grafico? Ecco, la linea tratteggiata rappresenta la parità rispetto al chip Intel.
Quindi tutto quello che c’è nell’angolo in basso a sinistra rappresenta combinazioni compito/ hardware che sono più veloci o meno energivore del chip Intel.
Mentre tutto quello che c’è al di là della linea tratteggiata riguarda soluzioni in confronto alle quali Loihi risulta più vantaggioso.
Quello che notiamo Innanzitutto è la diversità di risultati in funzione del compito che affrontiamo.
In secondo luogo, come per moltissimi compiti, soprattutto dinamici, come la classificazione di sequenze, evidenziato con l’area delineata da una linea tratteggiata in verde, Loihi sia particolarmente vantaggioso.
Complementare rispetto all’hardware neuromorfico è la metodologia del Reservoir computing.
Questo approccio si basa su una rete dinamica tipicamente non addestrata, ma che funge da serbatoio – Reservoir – e un livello di output che invece viene addestrato.
Questo tipo di rete utilizza una dinamica complessa all’interno del reservoir per elaborare i dati in ingresso e fornire previsioni o classificazioni basati sugli stati interni della rete.
Il reservoir computing è particolarmente adatto per elaborare dati temporali e sequenze, quindi sistemi dinamici come segnali di riconoscimento vocale o movimenti.
Il focus e vantaggio del reservoir computing sta proprio nella definizione architetturale del serbatoio che, a differenza delle reti neurali tradizionali, non è addestrato ma sfrutta appieno il concetto di randomicità.
Alcune proprietà di sistemi dinamici stocastici, infatti, possono essere utilizzate a nostro vantaggio per manipolare e preservare l’informazione nel tempo.
La relazione tra calcolo neuromorfico e reservoir computing emerge nella struttura delle reti dinamiche e nella elaborazione parallela di informazioni complesse.
Il reservoir computing può essere implementato in hardware neuromorfico, dove la rete neuromorfica agisce come reservoir, come serbatoio, sfruttando la complessità delle connessioni neurali per generare una varietà di stati utili all’elaborazione.
In particolare, entrambi gli approcci sfruttano le capacità delle reti neurali di generare stati complessi in risposta a input sequenziali.
Nel calcolo neuromorfico questo avviene attraverso circuiti ispirati ai neuroni biologici, mentre nel reservoir computer si utilizza un sistema preconfigurato, quindi un’architettura cablata ad hoc per generare dinamiche interne complesse.
Un secondo elemento di convergenza è rappresentato dal focus sull’efficienza energetica.
Il calcolo neuromorfico è noto per l’efficienza energetica, un aspetto che diventa cruciale quando il reservoir computing è implementato in hardware neuromorfico consentendo di ottenere sistemi capaci da un lato di elaborare dati complessi ma anche di sostenere un consumo energetico ridotto.
In sostanza, il reservoir computing può essere considerato come un modello di calcolo facilmente implementabile sui sistemi neuromorfici sfruttando le loro capacità di elaborazione parallela e dinamica per eseguire compiti complessi come l’elaborazione di sequenze temporali, come dicevamo.
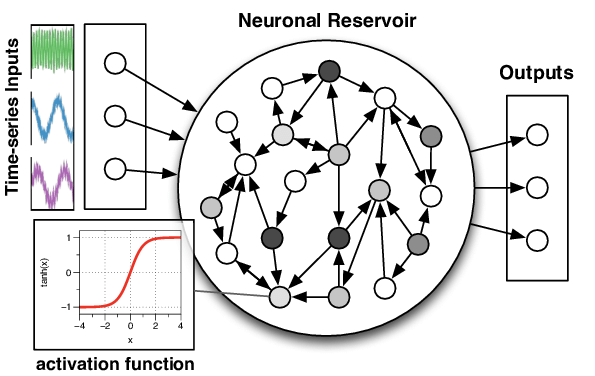
In questa immagine vediamo un esempio di reservoir computing classico per la modellazione di serie temporali multivariate, come vediamo in alto, raffigurate come sequenze di colori diversi, per esempio derivanti da sensori indossabili o dall’oscillazione del nostro smartphone.
Questo modello prende il nome di echo state network ed è basato su connessioni sparse e ricorrenti all’interno del Reservoir che vediamo al centro dell’immagine per elaborare e mantenere le informazioni storiche della sequenza in input.
Infine notiamo sulla destra un livello di output, chiamato read-out, che ci consente di leggere le informazioni di nostro interesse dal reservoir per effettuare, ad esempio una classificazione, ad esempio se stiamo andando in bicicletta o a piedi, a partire dalle sequenze delle misurazioni dell’oscillatore all’interno del nostro smartphone o smartwatch.
La letteratura scientifica suggerisce come le echo state network siano per molti compiti paragonabili alle reti neurali ricorrenti in termini di efficacia, ma offrono a volte degli speed-up fino a 1000 volte superiori, riducendo drasticamente le risorse computazionali necessarie per addestrare il modello predittivo.
In questa puntata abbiamo discusso di computazione neuromorfica e di come si stia lavorando a dei nuovi chip ispirati al cervello umano che possano consumare meno energia e superare l’architettura classica di Von Neumann, che vede una netta separazione tra memoria e calcolo.
Abbiamo anche discusso brevemente della complementarietà interessante con le metodologie di Reservoir Computing e di come questa combinazione possa risultare particolarmente allettante per il futuro dell’intelligenza artificiale.
Ciao! Alla prossima puntata di Le Voci dell’AI!