

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di un tema molto di tendenza nel contesto dell’intelligenza artificiale basata su apprendimento automatico – machine learning.
Parliamo di ragionamento e inferenza logica. È possibile pensare a soluzioni di AI che possono anche spiegare meglio il razionale delle loro scelte e, perché no, compierne di migliori, seguendo una serie di passaggi logicamente corretti di ragionamento?
Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Le soluzioni di intelligenza artificiale che puntavano a simulare il ragionamento umano si basavano su tecniche prettamente di inferenza logica, costruite principalmente attorno a rappresentazioni simboliche e regole deduttive, utilizzando quindi linguaggi formali come la logica proposizionale o quella del primo ordine.
Questi sistemi tentavano di riprodurre i processi decisionali attraverso una serie di regole – se succede questo, allora compio questa azione – per derivare nuove informazioni da quelle già disponibili.
L’obiettivo era costruire un sistema capace di risolvere problemi o rispondere a domande su contesti ben definiti tramite catene logiche che permettessero una forma di deduzione automatizzata.
Questo approccio, però presenta limiti evidenti: ogni sistema logico deve essere progettato specificatamente per il contesto in cui opera e non è in grado di adattarsi a situazioni nuove o applicazioni in domini differenti.
In questo contesto si inseriscono i famosi sistemi esperti, una delle prime applicazioni pratiche della logica dell’intelligenza artificiale, che utilizzavano un insieme di conoscenze specifiche di un settore come la medicina o la finanza, e un motore inferenziale per rispondere a problemi complessi, quasi sempre sotto supervisione umana.
Un esempio celebre è Mycin, sviluppato negli anni ’70 per la diagnosi di infezioni batteriche, che usava regole deduttive suggerite da medici esperti per fornire suggerimenti circa trattamenti specifici, dimostrando il potenziale dei sistemi basati sulla conoscenza formalizzata nel contesto della logica.
Tuttavia, nonostante i progressi ottenuti, la complessità computazionale e le risorse necessarie rendevano difficile estendere questi sistemi a un numero vasto di situazioni e ambiti, quindi riuscendo a generalizzare queste capacità di ragionamento.
Con l’avvento dei modelli di linguaggio su larga scala come i Large Language Models, si è aperta la strada a nuovi metodi per simulare ragionamenti complessi.
Tuttavia, fino a poco tempo fa era estremamente difficile per questi modelli realizzare veri e propri processi di inferenza logica, poiché la loro struttura basata su reti neurali profonde non era originariamente concepita per deduzioni logiche rigorose, ma per associare e generare pattern linguistici statisticamente rilevanti, spesso senza un reale ragionamento.
Ma, come abbiamo accennato in una precedente puntata di Le Voci dell’AI, stanno oggi emergendo sistemi come o1 di OpenAI, che cercano di implementare una catena di ragionamento – chain of thought – che, per quanto non abbia garanzie di correttezza, sembra realizzare due importanti vantaggi: da un lato migliorare la qualità delle risposte dettata da una o più dettagliato contesto, dall’altro rendere certe scelte più spiegabili e interpretabili.
In questa puntata volevo parlarvi di un recente studio della Carnegie Mellon University in collaborazione con Apple, dal titolo Improve Vision Language Model Chain of Thought Reasoning, che ci spiega un po’ meglio come questa catena di ragionamento possa essere implementata per migliorare le capacità di ragionamento dei modelli basati su visione e linguaggio.
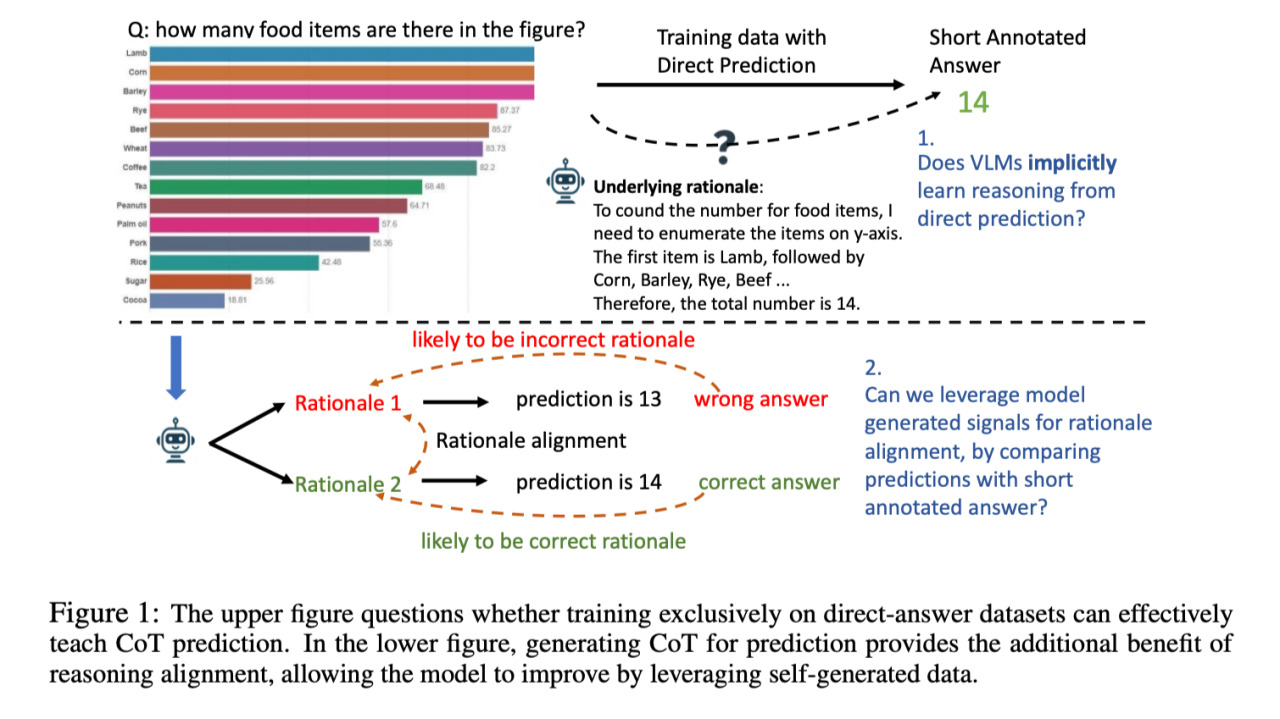
In questa immagine vediamo il funzionamento atteso dal sistema. In alto a sinistra vediamo un’immagine contenente un istogramma con diverse percentuali relative a 14 cibi diversi, come vedete sull’asse delle Y, sulle ordinate.
Se ponessimo quindi a un modello di question answering visivo la domanda: quanti cibi sono menzionati in questo diagramma non ci aspetterebbe solo un numero come risposta, ad esempio 14, quello corretto, ma anche una spiegazione, una serie di passi logici che porterebbero il sistema a quella risposta breve.
Questo, come già abbiamo ipotizzato ed è stato poi dimostrato empiricamente dallo studio in questione, porta direttamente a una correttezza migliore del modello nelle sue risposte.
Ecco come possiamo istruire un modello predittivo addestrato a fornire solo risposte brevi, a effettuare un vero e proprio processo di inferenza logica.
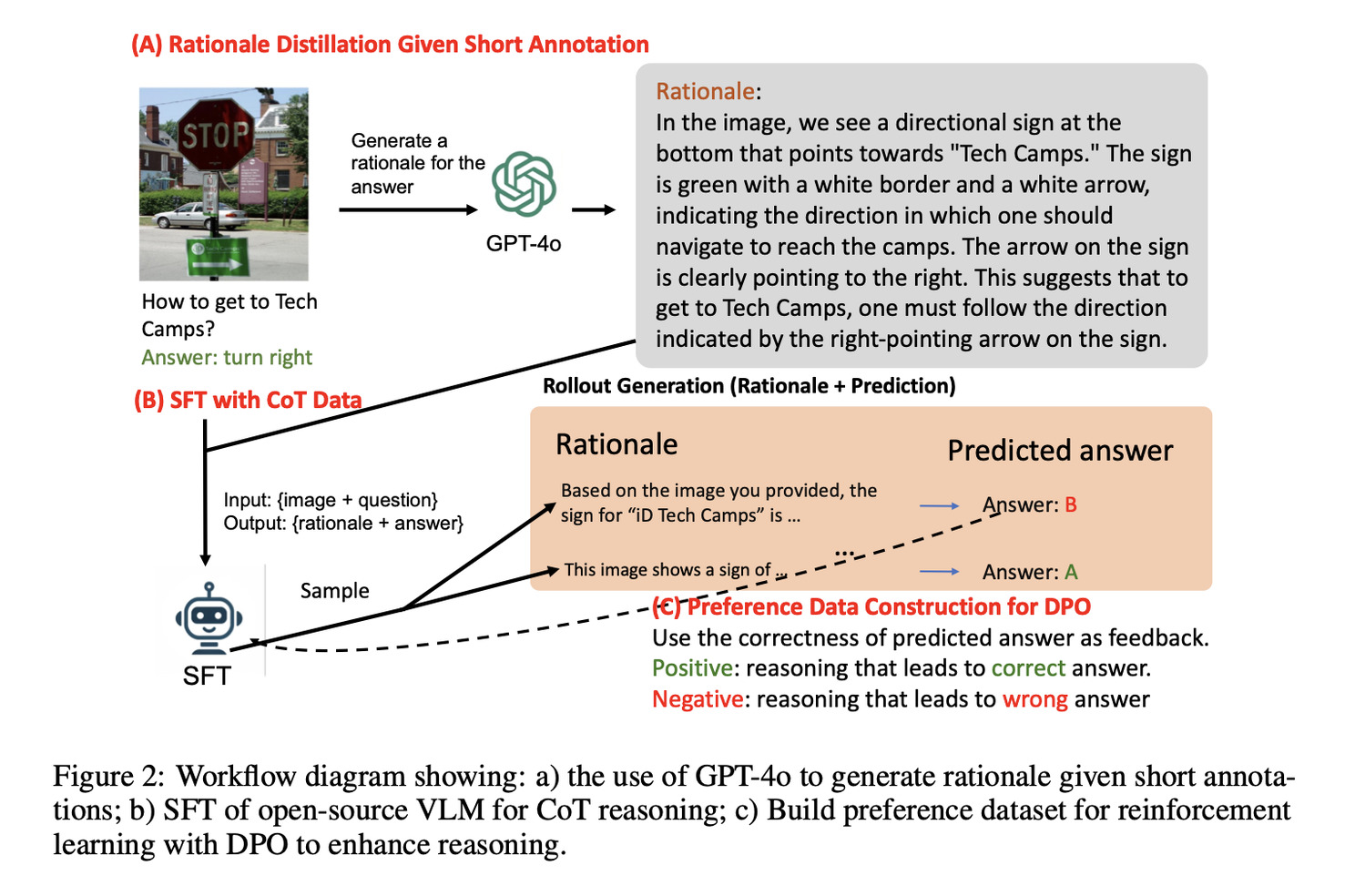
In questa immagine vediamo un possibile modo di addestrare un sistema a produrre una catena di pensieri in tre step.
Prima di tutto si sfrutta GPT-4o per generare passaggi di ragionamento dettagliati, quindi delle spiegazioni per dataset esistenti che contengono solo risposte brevi.
Questo processo crea un dataset completo di circa 200.000 esempi che coprono vari compiti dall’interpretazione dei grafici al ragionamento matematico.
Nella seconda fase, invece, il metodo utilizza il fine tuning supervisionato per addestrare il modello sia sulle risposte brevi, originali, sia sulle nuove spiegazioni dettagliate.
Questo doppio addestramento aiuta quindi il modello a imparare, sia a rispondere in modo conciso, sia a sviluppare capacità di ragionamento dettagliato.
Infine, in una terza fase si può ulteriormente migliorare la capacità di ragionamento, di chain of thought, del modello attraverso meccanismi di apprendimento con rinforzo tramite quella che viene chiamata ottimizzazione della preferenza diretta.
Il modello quindi genera diversi tentativi di ragionamento per ogni domanda e, confrontandoli con le risposte corrette, identifica i percorsi del ragionamento più probabilmente corretti.
Questo feedback, quindi, contribuisce a perfezionare ulteriormente il processo di ragionamento del modello senza richiedere dati aggiuntivi etichettati manualmente.
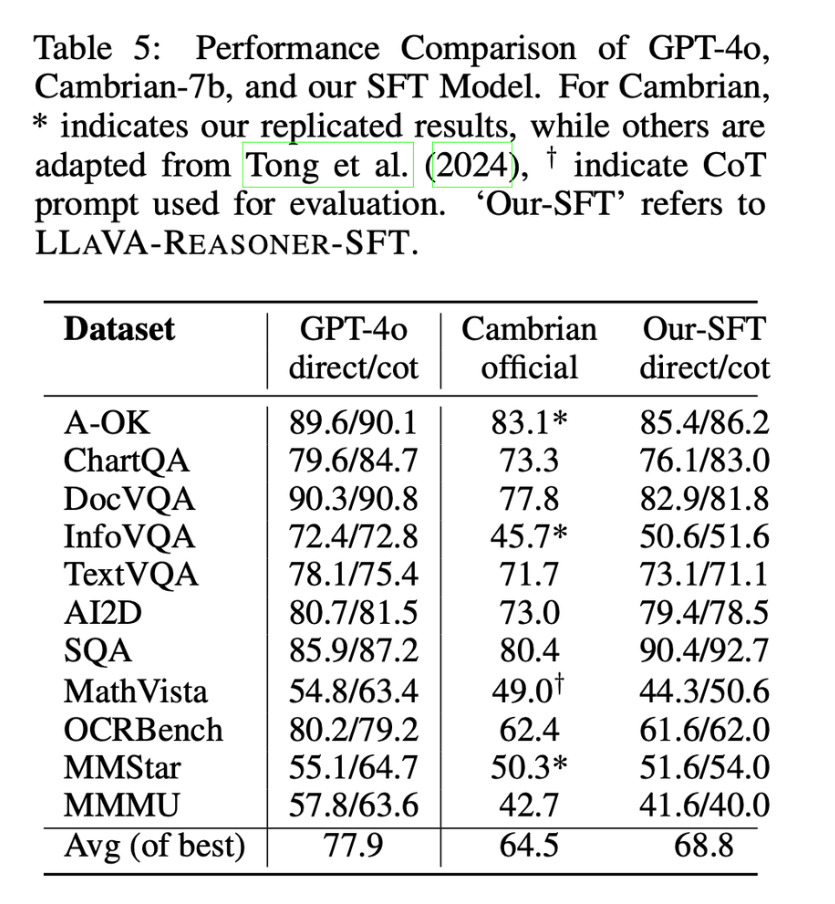
Infine, in questa immagine vediamo i risultati empirici dimostrati nell’articolo su diversi benchmark di ragionamento visivo.
Il modello proposto nella prima colonna mostra miglioramenti significativi sia nella previsione diretta delle risposte sia nel ragionamento passo passo evidenziato con l’acronimo CoT.
I progressi sono particolarmente evidenti nei compiti che richiedono calcoli e ragionamenti complessi e la metodologia si generalizza efficacemente su diversi tipologie di compiti, dalla lettura di grafici al ragionamento scientifico.
Il modello potenziato con il terzo passo di rifinitura con apprendimento mediante rinforzo dimostra inoltre miglioramenti costanti nei task di riordinamento, soprattutto su domande complesse di livello universitario.
In questa puntata abbiamo discusso dell’importanza del ragionamento e di come modelli linguistici possano effettivamente approssimare l’inferenza logica, tradizionalmente ad appannaggio esclusivo di algoritmi di intelligenza artificiale simbolica, per effettuare conclusioni più robuste e più interpretabili.
Questi ragionamenti basati su cenote sembrano essere una strada molto promettente per la prossima generazione di modelli fondazionali multimodali, anche perché ci consentirebbero di utilizzare altri strumenti durante il ragionamento step by step, non necessariamente basati su apprendimento automatico.
Avrete notato come GPT-4o già utilizzi questa tecnica per darvi delle risposte più soddisfacenti, ad esempio per calcolare dei risultati numerici come tenda ad implementare un algoritmo in Python ed eseguirlo al fine di dare una risposta numericamente più corretta.
Ci aspettiamo quindi nel futuro grandi investimenti in questa direzione per migliorare questi approcci basati su Chain of Thoughts.
Ciao! Alla prossima puntata di Le Voci dell’AI!