


Le unità TPU (Tensor Processing Unit) di Google offrono un circuito ASIC progettato e ottimizzato per il machine learning. Questi acceleratori hardware sono disponibili, in varie versioni, sulla Google Cloud Platform. La soluzione Cloud TPU consente di addestrare ed eseguire i modelli machine learning in modo più rapido e riducendo i costi.
Google Cloud Platform offre una variegata gamma di acceleratori per il machine learning. Google ha di recente pubblicato un resoconto sulla comparazione in termini di costi e di performance. In un articolo incentrato in particolar modo sui pod Cloud TPU e su Google Cloud VM con GPU NVIDIA Tesla V100.
Pod Cloud TPU per il machine learning
I pod Cloud TPU sono al momento disponibili in versione alpha. Si tratta di supercomputer realizzati con centinaia di chip custom Tensor Processing Unit (TPU), progettati da Google. Nonché dozzine di macchine host, il tutto collegato tramite un’interconnessione ultra-veloce customizzata.
La simulazione condotta da Google è illustrata nel blog di Google Cloud. I risultati mostrati dall’azienda evidenziano che i pod Cloud TPU offrono un’accelerazione quasi lineare per il task di training su larga scala.
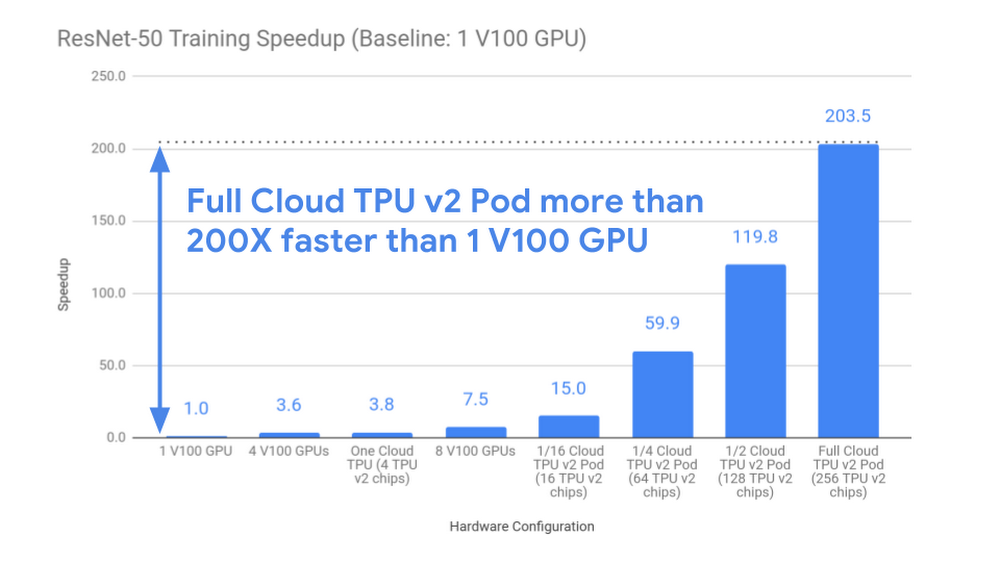 La configurazione maggiore di pod Cloud TPU testata (256 chip) ha offerto un’accelerazione di 200X rispetto a una singola GPU V100. Un’attesa di più di 26 ore su una GPU singola, benché allo stato dell’arte. Un pod Cloud TPU v2 completo offre lo stesso risultato in 7,9 minuti di tempo di training.
La configurazione maggiore di pod Cloud TPU testata (256 chip) ha offerto un’accelerazione di 200X rispetto a una singola GPU V100. Un’attesa di più di 26 ore su una GPU singola, benché allo stato dell’arte. Un pod Cloud TPU v2 completo offre lo stesso risultato in 7,9 minuti di tempo di training.
I costi del training di machine learning
Google affronta anche il tema dei costi del machine learning. Sottolineando innanzitutto che ridurre il costo del training machine learning consente a più professionisti del campo di esplorare una gamma più ampia di architetture di modelli. Nonché di addestrare modelli machine learning all’avanguardia su dataset più grandi e più rappresentativi.
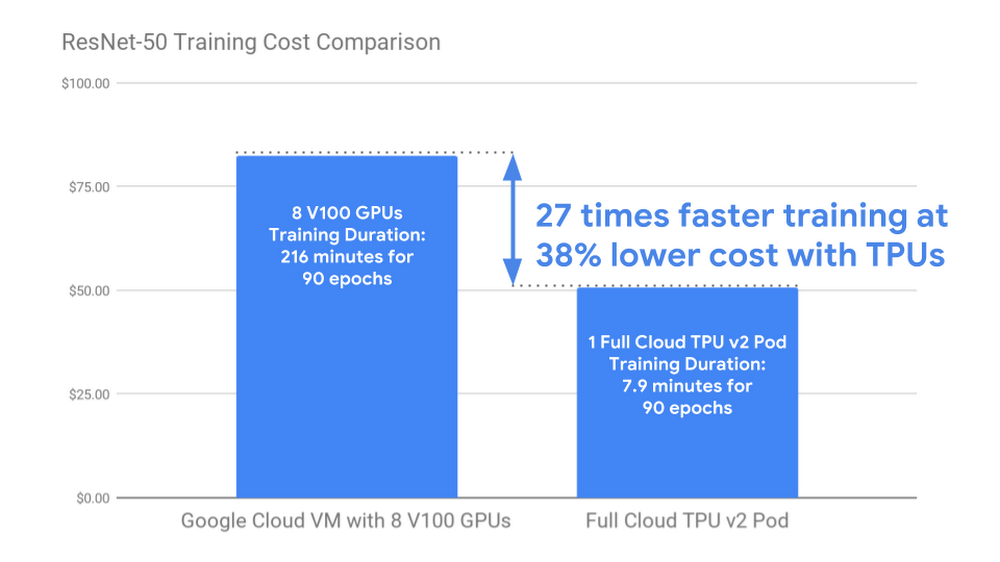 I dati Google mostrano che il training di ResNet-50 su un pod Cloud TPU v2 completo costa quasi il 40% in meno rispetto al training dello stesso modello con la stessa accuratezza su una Google Cloud VM n1-standard-64 con otto GPU V100 collegate. Oltre a questi risparmi, il pod Cloud TPU v2 completo esegue l’attività di training 27 volte più velocemente.
I dati Google mostrano che il training di ResNet-50 su un pod Cloud TPU v2 completo costa quasi il 40% in meno rispetto al training dello stesso modello con la stessa accuratezza su una Google Cloud VM n1-standard-64 con otto GPU V100 collegate. Oltre a questi risparmi, il pod Cloud TPU v2 completo esegue l’attività di training 27 volte più velocemente.
Le Cloud TPU sono progettate da zero in modo specifico per il machine learning. Consentono inoltre di scalare con grande flessibilità. Lo stesso codice che gira su una singola Cloud TPU può essere eseguito su un pod completo o su “slice” di dimensioni intermedie. Inoltre non necessitano che i data scientist debbano impostare server e configurazioni di rete complicati.
Maggiori informazioni sulle Cloud TPU di Google sono disponibili a questo link.









{kind=link}