


{kind=link}
Ferdinando Mancini, Director, Southern Europe Sales Engineering, Proofpoint, spiega perché Proofpoint ha costruito il suo modello linguistico di rete neurale invece di usare BERT o GPT.
I “modelli linguistici di grandi dimensioni” basati sulle reti neurali, come BERT, GPT e i loro successori, hanno rivoluzionato il campo dell’elaborazione del linguaggio naturale (Natural Language Processing – NLP). Mentre queste reti neurali generiche possono essere messe a punto per ottenere buone prestazioni in casi specifici, i modelli “tokenizer” su cui si basano non possono essere modificati.
In questo articolo dimostriamo che un tokenizer addestrato sul testo inglese potrebbe non analizzare in modo appropriato quello in una lingua diversa o i log generati dalle macchine (ad esempio, per l’analisi forense del malware). L’uso di un tokenizer personalizzato, tuttavia, richiede l’addestramento di una nuova rete neurale anziché la messa a punto di un modello linguistico esistente. In molti casi, l’uso di un tokenizer ottimizzato può consentire di utilizzare una rete neurale più piccola e performante e addestrarla su meno dati per un tempo inferiore.
Il team dei Machine Learning Labs di Proofpoint ha costruito un modello linguistico personalizzato per l’analisi forense del malware che funge da base per Camp Disco, il nostro motore di malware clustering. Ecco un’analisi più approfondita di ciò che è stato fatto, insieme a un’analisi di contesto.
L’ascesa dei modelli linguistici di grandi dimensioni

Dall’introduzione dell’architettura “Transformer” nel 2017, il campo della NLP è stato conquistato da “modelli linguistici” di reti neurali sempre più grandi, addestrati su un numero sempre maggiore di dati a costi sempre più elevati.
BERT è uno di questi modelli. È stato addestrato su oltre 3 miliardi di parole e viene utilizzato da Google per interpretare le ricerche degli utenti. GPT-3 è un altro modello enorme, con 175 miliardi di parametri apprendibili. Ha attirato l’attenzione per la sua capacità di creare testi realistici in vari contesti, da documenti accademici scritti da GPT-3 ad articoli a favore di un’intelligenza artificiale pacifica.
Questi “modelli linguistici di grandi dimensioni” (Large Language Models, LLM) hanno a loro volta generato una proliferazione di modelli derivati da LLM con obiettivi diversi: aumentare il throughput del modello, diminuirne le dimensioni senza sacrificarne le prestazioni (un processo noto come “distillazione”), ridurre la complessità della memoria e così via.
L’hub dei modelli di Hugging Face, ad esempio, contiene oltre 8.400 diversi modelli pre-addestrati in grado di eseguire la classificazione del testo (al 26 luglio 2022). Tra quelli disponibili vi sono:
- BERT (“bert-base-uncased”), 21 milioni di download a luglio 2022
- DistilBERT (“distilbert-base-uncased”), una versione ridotta di BERT, 10 milioni di download a luglio del 2022
- GPT-2 (“gpt2”), predecessore di GPT-3, 10 milioni di download a luglio 2022
- DistilGPT2 (“distilgpt2”), una versione ridotta e condensata di GPT-2, 4 milioni di download a luglio 2022
Per dimostrare quanto siano onnipresenti questi LLM, si consideri lo stato attuale di SuperGLUE: un benchmark comunemente utilizzato per monitorare i progressi di NLP. SuperGLUE mantiene una leaderboard che tiene traccia dei risultati dei modelli in otto diversi compiti di NLP, tra cui risposta alle domande, comprensione della lettura e disambiguazione del senso delle parole.
Al momento della pubblicazione di questo articolo (settembre 2022), 21 modelli hanno superato quello di base SuperGLUE: tutti e 21 sono basati su Transformer e 20 hanno più di 100 milioni di parametri addestrabili (compresi alcuni con oltre 100 miliardi di parametri addestrabili). Inoltre, sei LLM hanno superato il livello di base umano.
Di conseguenza, un paradigma sempre più comune nel machine learning moderno è quello di utilizzare un modello LLM o derivato da LLM (spesso una versione distillata di un LLM) e metterlo a punto su un particolare compito di interesse, invece di addestrare un intero modello da zero. Ciò consente ai professionisti di basarsi sulla conoscenza linguistica generalizzata contenuta in questi modelli, il che significa che il professionista ha bisogno di una quantità molto minore di dati etichettati per il compito di interesse.
Per analogia, immaginate di insegnare una nuova coreografia (il vostro compito) a un ballerino professionista (modello preformato) e a uno dilettante (modello non formato). In entrambi i casi, la coreografia è nuova e deve essere appresa. E, dato il tempo sufficiente per esercitarsi (dati etichettati), entrambe le persone possono produrre esibizioni di uguale qualità. Ma il ballerino professionista imparerà la coreografia molto più rapidamente, perché possiede già le conoscenze e l’esperienza fondamentali in materia di danza che mancano al dilettante.
Quindi, perché mai qualcuno dovrebbe scegliere di costruire da zero il proprio modello linguistico di rete neurale invece di utilizzare un modello derivato da LLM?
Un’introduzione alla tokenizzazione e al lessico
Le reti neurali operano fondamentalmente su tensori, matrici multidimensionali di numeri in virgola mobile. L’esecuzione di una sequenza di testo attraverso una rete neurale richiede quindi la trasformazione della sequenza di testo in un tensore. Questo processo è tipicamente diviso in due fasi:
- Tokenizzazione, dove la sequenza di testo viene convertita in una sequenza di interi.
- Embedding, dove ogni numero intero è sostituito da un vettore di numeri a virgola mobile.
Un tokenizer addestrato è definito da un vocabolario di “token”, un algoritmo utilizzato per apprendere il vocabolario ottimale sulla base di un corpus di testi e da un algoritmo utilizzato per prendere un nuovo testo e dividerlo in una sequenza di token del vocabolario.
Sebbene esistano diversi algoritmi di tokenizzazione, il fattore più importante che definisce un tokenizer è il modo in cui definisce un token. I tokenizer basati su parole separano il testo dagli spazi bianchi e dalla punteggiatura e aggiungono un token al vocabolario per ogni parola che osservano.
Ad esempio, la stringa “How are you” verrebbe rappresentata come la sequenza [“How”, “are”, “you”]. Al contrario, i tokenizer basati sui caratteri separano ogni carattere in un proprio token. Ad esempio, la stringa “How are you” diventerebbe [“H”, “o”, “w”, “_”, “a”, “r”, “e”, “_”, “y”, “o”, “u”].
| Sequenza | Tokenizer a parole | Tokenizer a caratteri |
| “How are you” | [How, are, you] | [H, o, w, _, a, r, e, _, y, o, u] |
| “I am fine” | [I, am, fine] | [I, _, a, m, _, f, i, n, e] |
A differenza dei tokenizer basati su parole, quelli basati sui caratteri perdono il significato semantico delle parole o delle loro radici e dipendono interamente dalla rete neurale a valle per imparare il significato dei diversi caratteri nelle diverse parole. Tuttavia, i tokenizer basati sui caratteri sono estremamente versatili: possono rappresentare tutte le sequenze con un vocabolario piuttosto ridotto (essenzialmente, l’insieme dei simboli di una tastiera).
I tokenizer basati su parole, invece, sono fortemente limitati dai loro vocabolari appresi. Se una parola non esiste nel vocabolario del tokenizer, viene rappresentata come un token speciale “fuori vocabolario”, anche se è molto simile a un token noto (per esempio, un errore di ortografia o un diverso significato).
I tokenizer di sottoparole sono stati introdotti di recente e mirano a ottenere il meglio di entrambi i mondi. In questi, il vocabolario è composto da “sottoparole” di lunghezza arbitraria, che possono corrispondere a singoli caratteri (al minimo), e a intere parole (al massimo).
Alcuni tokenizer di sottoparole distinguono anche tra i token all’inizio di una parola e quelli all’interno della parola (che di solito sono preceduti da “##”). Esistono diversi algoritmi per l’apprendimento e l’applicazione dei vocabolari di sottoparole, ma fondamentalmente producono tokenizzazioni che si avvicinano molto di più al modo in cui l’uomo analizza le parole. Ad esempio:
“read” -> [read]
“reads” -> [read, ##s]
“reading” -> [read, ##ing]
“reader” -> [read, ##er]
I tokenizer di sottoparole sono quindi diventati lo standard di fatto per i modelli linguistici basati sul deep learning, compresi gli LLM.
Lo step finale della tokenizzazione è comune a tutte le tipologie. Una semplice ricerca nel dizionario sostituisce i singoli token con indici interi unici (tipicamente corrispondenti alla posizione del token nel vocabolario appreso dal tokenizer). Questo completa la trasformazione da una sequenza di caratteri testuali a una sequenza di numeri interi.
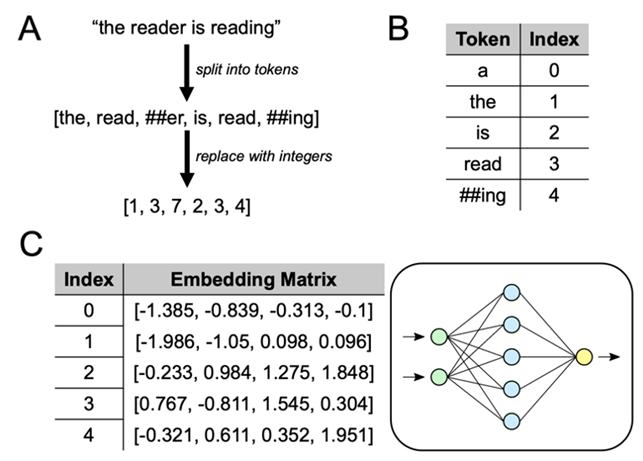
La sezione A della Figura 1 mostra il processo di tokenizzazione end-to-end con un vocabolario appreso (vedi sezione B).
La fase di incorporazione è relativamente semplice. Ogni numero intero viene sostituito dal corrispondente vettore di righe estratto da una “matrice di incorporazione” (si veda la sezione C della Figura 1). Questa matrice di incorporazione fa parte dell’insieme dei parametri apprendibili della rete neurale a valle e viene appresa durante l’addestramento del modello. Nel caso di modelli derivati da LLM, il tokenizer pre-addestrato e la matrice di embedding possono essere presi dall’LLM originale e solo il resto della rete neurale viene appreso nuovamente.
In pratica, ciò significa che qualsiasi modello LLM o derivato da LLM ha alla base un vocabolario (appreso dal tokenizer) e una matrice di incorporazione (che ha un vettore di righe per ogni elemento del vocabolario). Questo è uno dei motivi principali per cui un LLM addestrato solo su testi in inglese avrà scarse prestazioni su testi in francese, tedesco o qualsiasi altra lingua. Il vocabolario appreso dal tokenizer (e la matrice di incorporamento associata) è intrinseco all’insieme dei dati di addestramento e il testo francese o tedesco appare sostanzialmente diverso da quello inglese.
Mentre è possibile prendere un tokenizer e una matrice di incorporazione pre-addestrati e usarli come base di una nuova rete neurale, l’inverso non è generalmente vero: sostituendo tokenizer ed embedding di un LLM pre-addestrato con nuovi componenti, si rompe fondamentalmente l’LLM.
Il linguaggio dell’analisi del malware
L’analisi e il rilevamento del malware riguardano in larga misura l’analisi forense statica e comportamentale. Queste informazioni forensi possono assumere molte forme diverse: URL, percorsi di file, nomi di funzioni API di Windows e altro ancora. Sebbene molti di questi elementi forensi possano talvolta sembrare vagamente simili all’inglese, essi costituiscono chiaramente una lingua propria con convenzioni ortografiche e grammaticali molto diverse.
Cosa succede quando applichiamo un tokenizer addestrato sul testo inglese a questi dati forensi? Prendiamo, ad esempio, l’URL inventato ma plausibile:
https://login.microsoftonline.foobar.gq/wp-includes/login.php
Un individuo con una certa esperienza di dominio può facilmente analizzare l’URL nei suoi elementi costitutivi: protocollo, dominio, host, TLD e così via. I TLD, in particolare, possono contenere sequenze di caratteri (ad esempio, “gq”) che difficilmente compaiono insieme in un normale testo inglese. In alcuni casi, i segmenti di stringa possono essere facilmente scomposti in “parole” distinte, nonostante l’assenza di spazi bianchi o di caratteri non alfanumerici che li separano (ad esempio, “microsoftonline” -> [“microsoft”, “online”]).
Tuttavia, far analizzare manualmente a un essere umano tutti gli URL, i percorsi dei file e le chiamate API che compaiono nelle analisi forensi delle minacce non è chiaramente un processo sostenibile. Possiamo invece provare a utilizzare un modello di tokenizer per imitare il modo in cui un essere umano potrebbe analizzare ogni elemento.
Il tokenizer utilizzato nel modello BERT è stato addestrato su 3,3 miliardi di parole inglesi, tratte principalmente da Wikipedia e dai libri. Quando applichiamo il tokenizer di BERT al nostro URL campione, possiamo identificare chiaramente le discrepanze tra i token prodotti e il modo in cui un umano analizzerebbe l’URL (vedi Figura 2, in alto). Al contrario, se addestriamo un tokenizer personalizzato direttamente sui dati forensi, otteniamo un tokenizer che analizza l’URL in modo molto più simile a come lo analizzerebbe un essere umano (vedi Figura 2, in basso):

Come detto in precedenza, il tokenizer è il fondamento di un LLM e non è pratico sostituirlo con una versione personalizzata, conservando la conoscenza contenuta nell’LLM.
Sebbene sia possibile per una rete neurale a valle (ad esempio, BERT) compensare una tokenizzazione subottimale, i miglioramenti riscontrati nelle prestazioni dello stato dell’arte su vari compiti di NLP dopo l’introduzione di tokenizer di sottoparole (rispetto a quelli basati su caratteri e parole usati in precedenza) suggeriscono che si tratta di una battaglia impari.
Allo stesso modo, anche se può essere possibile sfruttare un LLM pre-addestrato aumentando il suo tokenizer e la matrice di incorporazione con token specifici del dominio, ciò rappresenta una sfida significativa nella pratica (i cui dettagli esulano dallo scopo di questo articolo).
In questo caso, il team di Proofpoint ha scelto di evitare completamente gli LLM e di addestrare un tokenizer personalizzato e un modello linguistico a rete neurale. Nel complesso, siamo riusciti a utilizzare molti meno dati per produrre un tokenizer più piccolo ed efficace.
L’uso di un tokenizer più vicino al comportamento umano è una forma di pregiudizio induttivo, che ci ha permesso di costruire una rete neurale più piccola e addestrarla su meno dati senza sacrificare le prestazioni del modello. Questo modello linguistico personalizzato per un’analisi forense del malware costituisce la spina dorsale delle tecnologie Proofpoint come Camp Disco, un motore di clustering del malware utilizzato dal team di threat research di Proofpoint per identificare gli schemi nei dati delle minacce.
Utilizzando un modello linguistico addestrato specificamente per la forensics del malware, Camp Disco è in grado di identificare e far emergere nomi di file, URL e altri artefatti forensi associati a cluster di minacce correlate, consentendo ai clienti una più rapida identificazione e correlazione di minacce sia avanzate che di base.
Qual è l’approccio giusto?
Dall’introduzione di BERT e GPT, la NLP sta vivendo il suo “momento ImageNet“. I modelli linguistici di grandi dimensioni (e i modelli derivati da LLM), molti dei quali hanno implementazioni open-source liberamente disponibili, stanno conquistando il campo, rendendo sempre più facile per i professionisti del machine learning affrontare i propri problemi di NLP con prestazioni senza precedenti. Tuttavia, anche i modelli più grandi e potenti sono fondamentalmente “bloccati” nell’insieme di lingue su cui il modello e il suo tokenizer sono stati addestrati.
In questo articolo abbiamo affrontato il caso dell’applicazione di tecniche NLP alla forensics del malware e abbiamo dimostrato che un tokenizer addestrato su misura analizza i dati di input in modo molto più intuitivo e simile a un esperto rispetto al tokenizer utilizzato da BERT. Mentre gli LLM possono avere la flessibilità e la complessità necessarie per apprendere bene anche con una tokenizzazione non ottimale, l’uso di un tokenizer personalizzato può aiutare a raggiungere livelli elevati di prestazioni con un modello più piccolo e meno dati di addestramento.