


Oggi è difficile incontrare uno sviluppatore che non usi Git e GitHub nel suo lavoro. Sono in effetti due strumenti per il controllo delle versioni che si adattano molto bene ai modelli di sviluppo di concezione moderna.
Permettono in particolare di lavorare in maniera distribuita e di eseguire liberamente modifiche anche molto mirate al codice di partenza senza essere bloccati da meccanismi troppo rigidi, al contempo riducendo il rischio di rovinare la vita dei colleghi intervenendo sul loro lavoro.
Rispetto ad altri VCS (Version Control System), però, Git e quindi anche GitHub adottano un modello diverso nella gestione dei progetti, proprio perché sono concettualmente sistemi distribuiti. Questo significa che il singolo sviluppatore lavora su un suo repository locale e si interfaccia (ma non necessariamente) con un repository centrale che fa da snodo per la collaborazione.
I VCS, poi, solitamente tengono traccia delle modifiche a un progetto esaminando le modifiche apportate ai suoi singoli file. Git ragiona diversamente e considera sempre un repository come una sorta di piccolo filesystem autonomo di cui realizzare veri e propri snapshot. Una modifica a un file è quindi vista come una modifica a tutto un repository e basta a generare uno snapshot completo, anche se per ovvie ragioni Git non replica i file che non sono stati modificati ma inserisce un puntatore alla versione precedente.
 C’è quindi un po’ di teoria da capire prima di tuffarsi in Git e GitHub. Online non mancano le guide, da quelle più semplici a quelle davvero approfondite, e capire le basi della piattaforma è meno arduo di quanto sembri. Qui non vogliamo presentare un manuale di Git, semplicemente indicare dieci “tips” che possono essere d’aiuto.
C’è quindi un po’ di teoria da capire prima di tuffarsi in Git e GitHub. Online non mancano le guide, da quelle più semplici a quelle davvero approfondite, e capire le basi della piattaforma è meno arduo di quanto sembri. Qui non vogliamo presentare un manuale di Git, semplicemente indicare dieci “tips” che possono essere d’aiuto.
Convivere con i client
Ci sono molti modi per usare Git. Il principale è usare proprio Git in senso stretto, ossia l’interfaccia a linea di comando originariamente sviluppata da Linus Torvalds stesso oltre dieci anni fa. Questo volto di Git è in tutti i sistemi Linux e si può installare in tutti i principali sistemi operativi. Non è obbligatorio usare la CLI, però. Specie se decidiamo – e di solito accade – di usare GitHub, che in sintesi è un repository pubblico (e privato) basato su interfaccia web. Si può usare questa oppure il suo client nativo (Windows o Mac) oppure ancora altri client grafici. Ce ne sono gratuiti e a pagamento.
Clonare liberamente da GitHub
GitHub è pieno di progetti che possono essere interessanti ed è molto utile clonarli. Il cloning di un progetto è in sintesi la copia di tutto il suo repository (repo, in breve) sul nostro client. La clonazione ci permette di esaminare in dettaglio e comodamente il codice e la documentazione, per imparare qualcosa in più nello sviluppo o più genericamente per vedere come è stato affrontato un certo problema. Possiamo anche usare il codice del progetto clonato in altri nostri progetti, a patto che la licenza del progetto lo preveda e nell’ambito dei limiti che essa impone. Si noti che anche dopo aver clonato un repository siamo ancora nell’ambito di ciò che facciamo noi sul nostro client. Di modifiche al progetto originario ne parliamo più avanti.
Le regole del commit
Abbiamo creato (da zero o clonato) un nostro repository locale e iniziamo a lavorare. Git è un ambiente distribuito, questo vuol dire che le modifiche avvengono in locale e i cambiamenti hanno effetto solo qui. Un commit è una qualsiasi modifica che abbiamo apportato, anche piccola, e che “ratifichiamo” come parte accettata del progetto stesso. Qualsiasi modifica che testiamo non esiste (in senso lato) per Git finché non ne eseguiamo il commit. Che ha valore – va ribadito – solo per il repository locale.
Due corollari da questo ragionamento: meglio eseguire commit frequenti e meglio commentarli bene. I commit frequenti servono a mantenere uno storico preciso e granulare del nostro sviluppo, i commit commentati bene sono più facili da comprendere per tutti quelli che vedranno il nostro lavoro. E no, commentare il codice in sé non è la stessa cosa.
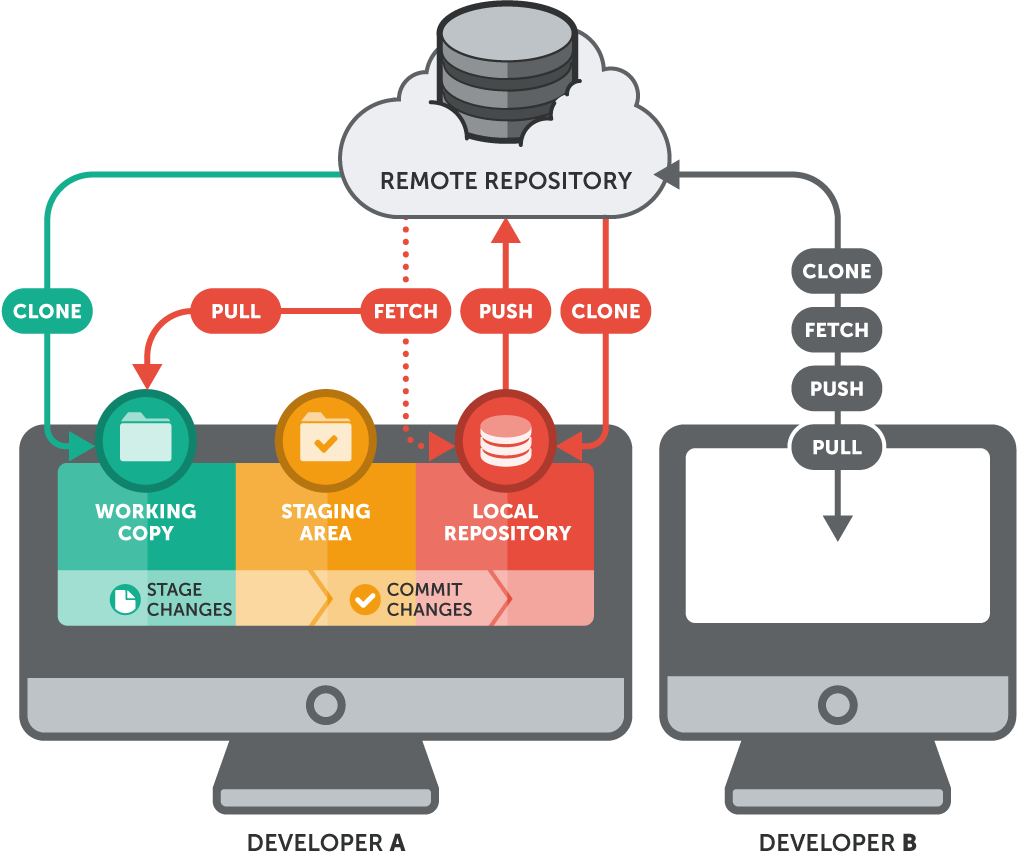 Tra push e pull
Tra push e pull
Idealmente, Git fa da supporto a uno o più progetti in cui un team di sviluppatori distribuito porta avanti le sue attività di sviluppo. Ognuno clona il suo repository e lavora alla sua parte, ma deve quasi certamente essere allineato con quello che sviluppano i colleghi. La prima cosa da fare è quindi eseguire frequentemente il pull del repository, operazione che recepisce le modifiche apportate alla versione principale sul server.
Analogamente, noi possiamo anche aver sviluppato elementi di codice perfetti e corretto tutti gli errori correggibili, ma fin quando non eseguiamo il push del repository locale, nessuno vedrà il frutto del nostro lavoro. Si noti che un commit non equivale a un push: la prima operazione agisce solo in locale, la seconda sul server. Non eseguire nel modo ideale pull e push è la causa più comune di incongruenze nello sviluppo di un team distribuito. Git in parte aiuta a evitare questi problemi ma non li può eliminare del tutto.
La potenza del branching
Uno dei punti di forza migliori di Git è che si adatta alla realtà delle attività di sviluppo, senza ispirarsi a un modello ideale in cui tutte le attività di programmazione vanno sempre come in teoria dovrebbero. Come prima cosa prevede un meccanismo – il branching – per cui uno sviluppatore può dedicarsi tranquillamente a una particolare funzione di un programma senza bloccare il lavoro degli altri e senza rigidità. Tanto che lo si può fare ogni volta che si vuole, ragionevolmente sicuri che Git recepirà lo sviluppo parallelo senza (particolari) problemi.
Quando vogliamo lavorare su un particolare aspetto del codice lasciando che la parte principale del progetto vada avanti, ne creiamo una branch (ramificazione). Da qui in poi lavoriamo solo sulla branch, completiamo il nostro obiettivo (ad esempio modificare una particolare funzione) e poi eseguiamo il merge del nostro codice con la parte principale del progetto. Se avvengono dei conflitti in questa incorporazione, sta a noi risolverli (spesso è solo qualche commit che si è perso per strada).
Ma la vita del programmatore non è sempre così lineare. Ammettiamo di stare lavorando sulla nostra branch e che d’improvviso ci venga chiesto di tornare a lavorare sulla versione principale del progetto o su un’altra branch. Ovviamente si può fare, ma cosa succede al lavoro che abbiamo portato avanti e di cui magari non abbiamo ancora eseguito un commit? Niente paura: git si adatta e prevede il comando stash che salva tutte le modifiche in una sorta di branch temporanea alla quale si può ritornare dopo l’interruzione.
Fork non è branch
In alternativa al branching spesso si parla anche del forking di un repository Git. In realtà si tratta di due concetti molto diversi e che non sono, a rigor di logica, strettamente paragonabili. Il forking non è un elemento di Git (non esiste un comando git-fork, per dire) ma di GitHub e di sistemi simili: serve nella pratica a creare una copia server del repository di partenza, quasi sempre per portare avanti il progetto seguendo una direzione diversa da quella attuale.
Non è necessariamente un’azione di rottura, per molti progetti open source è del tutto lecito realizzare adattamenti propri o versioni ad hoc. Di fatto però creiamo un progetto distinto con un suo repository autonomo. Se poi vogliamo che questo sviluppo venga integrato nel progetto originario non possiamo procedere per commit e push, perché non abbiamo i necessari privilegi sul progetto di partenza.
Il meccanismo in questo caso è quello delle pull request: chiediamo che i responsabili del progetto di partenza “acquisiscano” le nostre modifiche. Queste ovviamente non sono accettate a scatola chiusa, vengono valutate e possono anche essere rifiutate. O può esserci chiesto di adattarle alle necessità del progetto.
Essere buoni cittadini di GitHub
GitHub è una piattaforma, certo, ma è anche un vero e proprio mondo da esplorare con migliaia di progetti molto diversi fra loro. Come in qualsiasi community, esserne membri attivi è positivo e gratificante.
Ad esempio si può contribuire, nella misura delle proprie capacità, ai progetti open source. Esaminando la loro documentazione possiamo scoprire modi di fare parte dei progetti anche molto semplici, che non richiedono abilità estreme nella scrittura del codice.
Essere buoni cittadini di GitHub consiste anche nel presentarsi bene. O meglio nel presentare bene i propri progetti, in primis descrivendoli in maniera precisa e completa. Tenete presente che alla descrizione del vostro progetto possono arrivare utenti molto tecnici – magari altri sviluppatori – ma anche con competenze di sviluppo limitate. Tutti devono comunque capirci qualcosa e soprattutto cosa fa e perché dovrebbe essere utile la vostra creazione. Un dettaglio, ma non trascurabile: ormai il formato standard per la documentazione in questi casi è Markdown, per GitHub ne esiste anche una versione specifica.









{kind=link}
mai trovata una spiegazione tanto chiara e sintetica. grazie!
complimenti, la figura nel paragrafo “le regole del commit” è incredibilmente esplicativa e facilita la comprensione della guida ufficiale.
grazie, molto utile.