


{kind=link}
Stability AI ha presentato Stable Audio 2.0, modello che consente di ottenere tracce complete di alta qualità con una struttura musicale coerente e in grado di produrre fino a tre minuti di lunghezza a 44,1 kHz stereo da un singolo prompt in linguaggio naturale.
Il nuovo modello – sottolinea la società sviluppatrice – va oltre il text-to-audio e include funzionalità audio-to-audio. Gli utenti possono ora caricare campioni audio e trasformarli in un’ampia gamma di suoni attraverso prompt in linguaggio naturale.
Questo aggiornamento, spiega Stability AI, amplia anche la generazione di effetti sonori e il trasferimento di stili, offrendo ad artisti e musicisti maggiore flessibilità, controllo e un processo creativo più elevato.
Stable Audio 2.0 si basa su Stable Audio 1.0, che ha debuttato nel settembre 2023 come primo strumento di generazione musicale AI commercialmente valido in grado di produrre musica di alta qualità a 44,1 kHz, sfruttando la tecnologia latent diffusion. Da allora è stato nominato dal TIME una delle migliori invenzioni del 2023.
Questo nuovo modello è disponibile gratuitamente sul sito web di Stable Audio e sarà presto disponibile con l’API Stable Audio.
Quello che è il modello audio più avanzato di Stability AI amplia il kit di strumenti creativi messi a disposizione di artisti e musicisti, con le sue nuove funzionalità. Grazie al prompting sia text-to-audio che audio-to-audio, gli utenti possono produrre melodie, backing track, tracce ed effetti sonori, migliorando così il processo creativo.
Stable Audio 2.0 si distingue da altri modelli all’avanguardia perché è in grado di generare brani della durata massima di tre minuti, completi di composizioni strutturate che includono un’introduzione, uno sviluppo e un’outro, oltre a effetti sonori stereo.
Il nuovo modello amplifica la produzione di suoni ed effetti audio, dal battito di una tastiera al boato di una folla o al ronzio delle strade cittadine, offrendo nuovi modi per sviluppare i progetti audio.
La nuova funzione Style Transfer modifica senza soluzione di continuità l’audio appena generato o caricato durante il processo di generazione. Questa funzionalità consente di personalizzare il tema dell’output, per allinearlo allo stile e al tono specifici di un progetto.
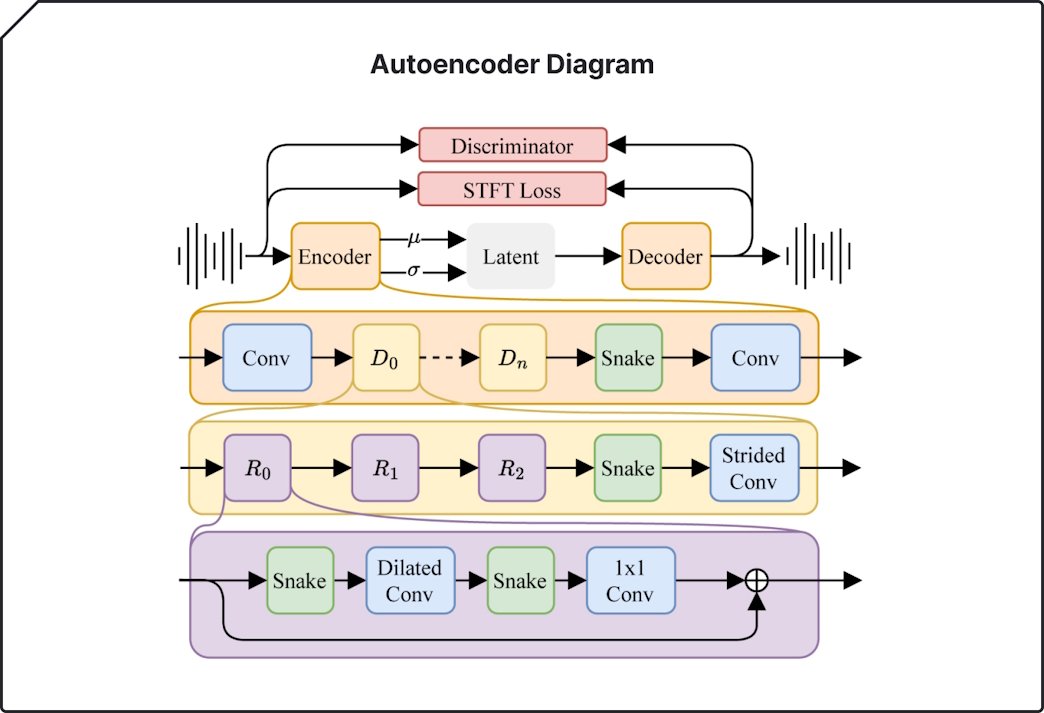
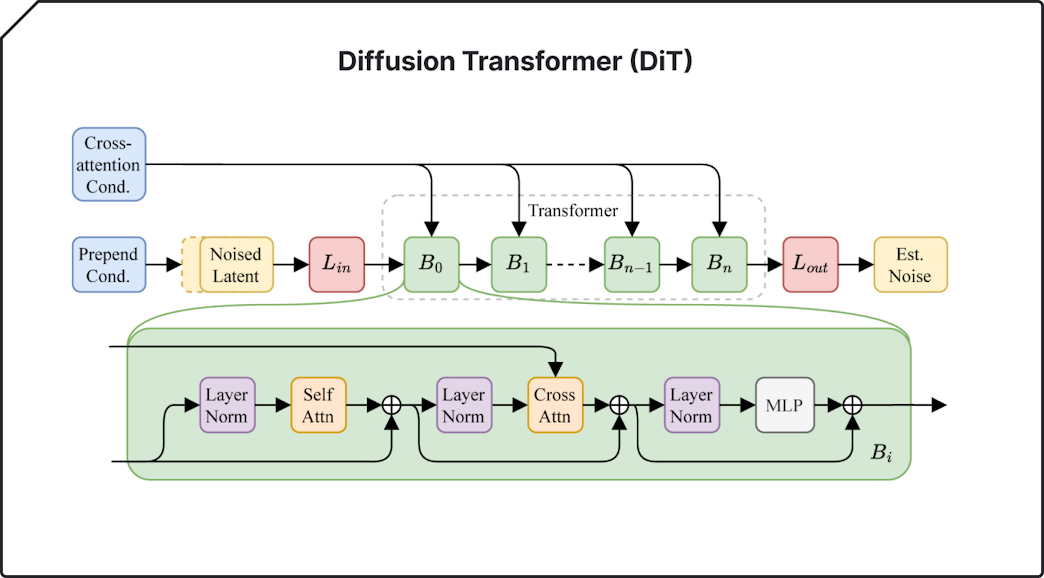
L’architettura del modello latent diffusion di Stable Audio 2.0 – sottolinea Stability AI – è stata progettata appositamente per consentire la generazione di tracce complete con strutture coerenti. Per ottenere questo risultato, il team ha adattato tutti i componenti del sistema per migliorare le prestazioni su lunghe scale temporali.
Un nuovo autoencoder altamente compresso comprime le forme d’onda audio grezze in rappresentazioni molto più brevi. Per il modello diffusion, viene utilizzato un diffusion transformer (DiT), simile a quello utilizzato in Stable Diffusion 3, al posto della precedente U-Net, in quanto più abile nel manipolare i dati su lunghe sequenze. La combinazione di questi due elementi dà vita a un modello in grado di riconoscere e riprodurre le strutture su larga scala che sono essenziali per composizioni musicali di alta qualità.
 Come il modello 1.0, anche la versione 2.0 è stata addestrata su dati provenienti da AudioSparx, costituiti da oltre 800.000 file audio contenenti musica, effetti sonori e tracce di singoli strumenti, oltre ai corrispondenti metadati testuali. A tutti gli artisti di AudioSparx è stata data la possibilità di non partecipare al training del modello Stable Audio.
Come il modello 1.0, anche la versione 2.0 è stata addestrata su dati provenienti da AudioSparx, costituiti da oltre 800.000 file audio contenenti musica, effetti sonori e tracce di singoli strumenti, oltre ai corrispondenti metadati testuali. A tutti gli artisti di AudioSparx è stata data la possibilità di non partecipare al training del modello Stable Audio.
Per proteggere i diritti d’autore dei creatori, per gli upload audio Stability AI collabora con Audible Magic e utilizza la sua tecnologia di content recognition (ACR) per fare il matching dei contenuti in tempo reale e prevenire le violazioni dei diritti d’autore.
Stable Radio, un flusso live 24/7 che presenta brani generati esclusivamente da Stable Audio, è ora in streaming sul canale YouTube di Stable Audio.