


{kind=link}
Stability AI ha pubblicato un paper di ricerca che approfondisce la tecnologia sottostante a Stable Diffusion 3, che è attualmente in early preview.
Secondo Stability AI, Stable Diffusion 3 supera i sistemi di generazione text-to-image più avanzati, come DALL-E 3, Midjourney v6 e Ideogram v1, per quanto riguarda la tipografia e l’aderenza alle richieste, sulla base di valutazioni delle preferenze umane.
La nuova architettura Multimodal Diffusion Transformer (MMDiT) – spiega il team – utilizza set di pesi separati per le rappresentazioni delle immagini e del linguaggio, migliorando la comprensione del testo e le capacità ortografiche rispetto alle versioni precedenti.

Il paper sul prossimo modello di Stability AI è accessibile su arXiv mentre è possibile iscriversi alla lista d’attesa per partecipare all’anteprima.
Stability AI ha confrontato le immagini in output da Stable Diffusion 3 con vari altri modelli open, tra cui SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 e Pixart-α, nonché con sistemi closed-source come DALL-E 3, Midjourney v6 e Ideogram v1 per valutare le prestazioni sulla base del feedback umano.
Durante questi test, ai valutatori umani sono stati forniti esempi di output di ciascun modello ed è stato chiesto loro di selezionare i risultati migliori in base a quanto gli output del modello seguissero il contesto del prompt che gli era stato dato (“prompt following“), a quanto bene il testo fosse reso in base al prompt (“typography“) e a quale immagine fosse di maggiore qualità estetica (“visual aesthetics“).
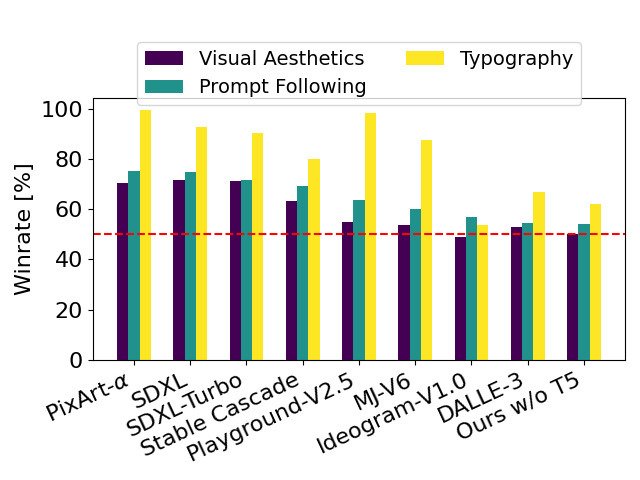
Dai risultati dei test di Stability AI, l’azienda ha riscontrato che Stable Diffusion 3 è pari o superiore agli attuali sistemi di generazione immagini dal testo allo stato dell’arte in tutte le aree sopra citate.
Nei primi test di inferenza non ottimizzati su hardware consumer, il modello Stable Diffusion 3 più grande con 8B parametri si adatta alla VRAM da 24 GB di una RTX 4090 e impiega 34 secondi per generare un’immagine di risoluzione 1024×1024 utilizzando 50 passi di campionamento.
Stability AI ha inoltre annunciato che durante il rilascio iniziale saranno disponibili diverse varianti di Stable Diffusion 3, che vanno dai modelli a 800M a quelli a 8B parametri, per eliminare ulteriormente le barriere hardware.

Sul sito di Stability AI è possibile visualizzare alcuni esempi di generazione text-to-image e leggere dettagli tecnici del nuovo modello.