


{kind=link}
Meta ha annunciato di aver progettato e costruito l’AI Research SuperCluster (RSC), che l’azienda ritiene essere tra i più veloci supercomputer di intelligenza artificiale in funzione oggi.
E che – sottolinea ancora Meta – sarà il più veloce supercomputer di intelligenza artificiale del mondo quando la sua realizzazione sarà del tutto completata, a metà del 2022.
I ricercatori di Meta hanno già iniziato a usare il Research SuperCluster per addestrare modelli di grandi dimensioni nell’elaborazione del linguaggio naturale (NLP) e nella computer vision per la ricerca.
L’obiettivo è quello di poter eseguire in futuro il training di modelli con migliaia di miliardi di parametri.
L’obiettivo è che il Research SuperCluster aiuti i ricercatori di Meta a costruire modelli di intelligenza artificiale nuovi e migliori, che possono imparare da migliaia di miliardi di esempi.
E capaci di lavorare in centinaia di lingue diverse, analizzare senza soluzione di continuità testo, immagini e video insieme, sviluppare nuovi strumenti di realtà aumentata, e molto altro.
I ricercatori – ha dichiarato Meta – saranno in grado di addestrare i modelli più grandi necessari per sviluppare l’intelligenza artificiale avanzata per la computer vision, l’NLP (natural language processing), il riconoscimento vocale e altro ancora.

Meta si augura che RSC possa contribuire a costruire sistemi di intelligenza artificiale completamente nuovi che possano accelerare l’innovazione per molti casi d’uso.
Ad esempio, per fornire traduzioni vocali in tempo reale ad ampi gruppi di persone, ognuna delle quali parla una lingua diversa, in modo che possano collaborare senza problemi.
E, coerentemente con la vision di Meta, il lavoro fatto con RSC aprirà la strada verso la costruzione di tecnologie per la prossima grande piattaforma informatica.
Vale a dire, per l’azienda di Mark Zuckerberg: il metaverso, dove le applicazioni e i prodotti potenziati dall’intelligenza artificiale avranno un ruolo importante.
Perché un tale supercomputer serve
Meta è impegnata in investimenti a lungo termine nell’intelligenza artificiale dal 2013, quando fu creato il Facebook AI Research lab.
Negli ultimi anni l’azienda ha fatto passi avanti significativi in una serie di aree, tra cui l’innovazione nell’apprendimento auto-supervisionato, in cui gli algoritmi possono imparare da un gran numero di esempi non etichettati. E nei Transformer, che consentono ai modelli di intelligenza artificiale di ragionare in modo più efficace focalizzandosi su alcune aree del loro input.
Per realizzare appieno i vantaggi dell’apprendimento auto-supervisionato e dei modelli basati su Transformer – ha spiegato Meta –, vari domini richiederanno il training di modelli sempre più grandi, complessi e adattabili.
L’high-performance computing è un componente critico nel training di questi vasti modelli, e il team di Meta ha costruito tali sistemi per molti anni.
La prima generazione di questa infrastruttura, progettata nel 2017, ha 22.000 GPU Nvidia V100 Tensor Core in un singolo cluster che esegue 35.000 job di training al giorno.

All’inizio del 2020, Meta ha deciso che il modo migliore per accelerare i progressi in quest’area era quello di progettare una nuova infrastruttura di calcolo partendo da zero per sfruttare le nuove tecnologie di GPU e network fabric.
Meta voleva che questa infrastruttura fosse in grado di addestrare modelli con più di mille miliardi di parametri su set di dati enormi come un exabyte.
Il tutto, assicurandosi di avere tutti i controlli di sicurezza e privacy necessari per proteggere i dati di training. RSC permette infatti di includere esempi del mondo reale nel training dei modelli. E questo a sua volta aiuta a far progredire la ricerca e le implementazioni in molti ambiti.
Meta ritiene che il Research SuperCluster rappresenti la prima volta in cui le prestazioni, l’affidabilità, la sicurezza e la privacy siano state affrontate su tale scala.
Come è fatto il Research SuperCluster di Meta
I supercomputer per l’intelligenza artificiale – ha messo in evidenza Meta – sono costruiti combinando più GPU in nodi di calcolo, che sono poi collegati da un network fabric ad alte prestazioni per consentire la comunicazione rapida tra le GPU.
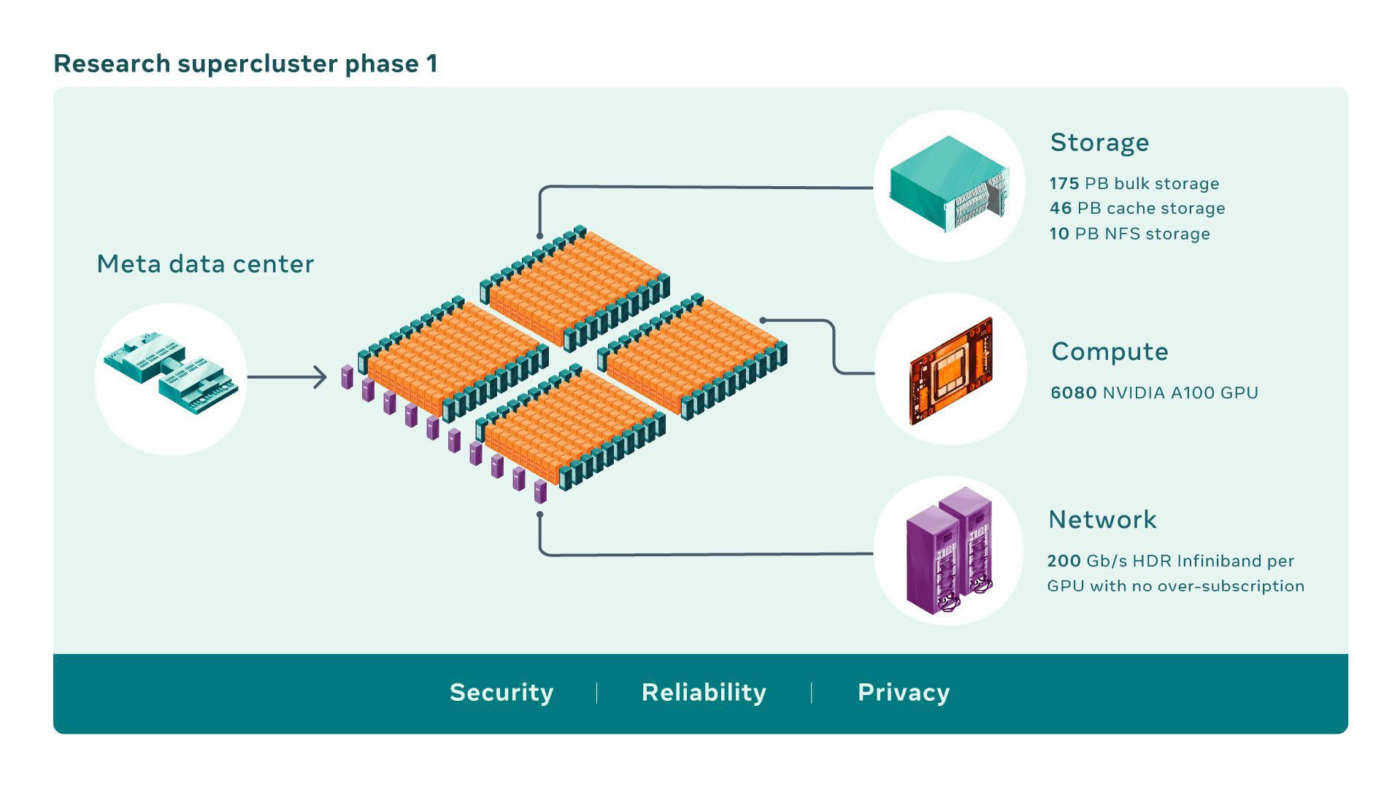
RSC oggi comprende un totale di 760 sistemi Nvidia DGX A100 come nodi di calcolo, per un totale di 6.080 GPU: ogni GPU A100 è più potente della V100 usata nel sistema precedente.
Le GPU comunicano tramite un fabric Clos a due livelli Nvidia Quantum 200 Gb/s InfiniBand che non ha oversubscription.
Il tier di storage di RSC ha 175 petabyte di Pure Storage FlashArray, 46 petabyte di storage cache nei sistemi Penguin Computing Altus e 10 petabyte di Pure Storage FlashBlade.

L’azienda ha dichiarato che i primi benchmark su RSC, confrontati con l’infrastruttura di produzione e ricerca legacy di Meta, hanno dimostrato che esegue workflow di computer vision fino a 20 volte più velocemente. Esegue la Nvidia Collective Communication Library (NCCL) più di nove volte più velocemente e fa il training dei modelli NLP su larga scala tre volte più velocemente.
Ciò significa – ha sottolineato Meta – che un modello con decine di miliardi di parametri può finire il training in tre settimane, rispetto alle nove settimane precedenti.
Meta ha anche sottolineato come i partner abbiano rivestito un ruolo importante nella realizzazione del supercomputer: Nvidia, Penguin Computing e Pure Storage.
Il progetto del Research SuperCluster ha presentato molte sfide di progettazione del data center, in vari ambiti: raffreddamento, alimentazione, disposizione dei rack, cablaggio e networking e altri ancora.
Non ultime, le difficoltà poste dalla pandemia di Covid-19 e i problemi delle supply chain degli ultimi periodi.
Storage e sicurezza
Oltre al sistema core, c’era anche la necessità di una soluzione di storage potente, che potesse servire terabyte di larghezza di banda da un sistema su scala exabyte.
Per questo, Meta ha sviluppato da zero anche un servizio di storage, AI Research Store (AIRStore).
Per ottimizzare i modelli di intelligenza artificiale, AIRStore utilizza una nuova fase di preparazione dei dati che preprocessa il dataset da utilizzare per il training.
AIRStore ottimizza anche i trasferimenti di dati in modo da ridurre al minimo il traffico sul backbone di Meta.
Per quanto riguarda la sicurezza, per costruire nuovi modelli di intelligenza artificiale che vadano a vantaggio degli utenti finali, occorre addestrare i modelli utilizzando dati del mondo reale dai sistemi di produzione, evidenzia Meta.
RSC è stato progettato da zero tenendo conto della privacy e della sicurezza, in modo che i ricercatori di Meta possano addestrare in modo sicuro i modelli utilizzando dati crittografati generati dagli utenti che non vengono decrittati fino a poco prima del training.
RSC è isolato da Internet, senza connessioni dirette in entrata o in uscita, e il traffico può fluire solo dai data center di Meta.
L’intero percorso dei dati – dai sistemi di storage alle GPU – è crittografato end-to-end. Inoltre, dispone degli strumenti e processi necessari per verificare che questi requisiti sono soddisfatti in ogni momento.
Prima che i dati siano importati in RSC, devono passare attraverso un processo di revisione della privacy per confermare che siano stati correttamente resi anonimi.
I dati vengono poi criptati prima di poter essere utilizzati per addestrare i modelli e le chiavi di decrittazione vengono cancellate regolarmente affinché i dati più vecchi non siano ancora accessibili.
E poiché i dati vengono decrittati solo in un endpoint, in memoria, sono salvaguardati anche nell’improbabile caso di una violazione fisica della struttura, sottolinea Meta.
Intelligenza artificiale del futuro
RSC è attivo e funzionante già oggi, ma il suo sviluppo è ancora in corso, ha affermato Meta.
Una volta completata la fase due della costruzione del Research SuperCluster, Meta crede che esso sarà il supercomputer per l’intelligenza artificiale più veloce del mondo, con quasi 5 exaflop di calcolo a precisione mista.
Meta è al lavoro per aumentare entro il 2022 il numero di GPU da 6.080 a 16.000, il che farà crescere le prestazioni di training dell’intelligenza artificiale di oltre 2,5 volte.
Il fabric InfiniBand si espanderà per supportare 16.000 porte in una topologia a due layer senza oversubscription.
Il sistema di storage avrà una larghezza di banda target di 16 TB/s e una capacità su scala exabyte per soddisfare l’aumento della domanda.
Meta si aspetta che un tale salto nella capacità di calcolo possa permettere all’azienda non solo di creare modelli di intelligenza artificiale più accurati per i servizi esistenti, ma anche di abilitare esperienze utente completamente nuove, specialmente nel metaverso.
Gli investimenti a lungo termine nell’apprendimento auto-supervisionato e nella costruzione dell’infrastruttura di intelligenza artificiale di prossima generazione con RSC, nella vision di Meta aiutano l’azienda a creare le tecnologie fondamentali che alimenteranno il metaverso.
E, secondo Meta, faranno anche progredire la più ampia community dell’intelligenza artificiale.