


{kind=link}
Come afferma il team di ricerca di Google Research, una recente ondata di modelli di generazione di video ha fatto il suo ingresso sulla scena, mostrando in molti casi una qualità pittorica sorprendente. Uno degli attuali colli di bottiglia nella generazione di video è la capacità di produrre movimenti coerenti e ampi. In molti casi, anche gli attuali modelli di punta generano movimenti piccoli o, quando producono movimenti più grandi, presentano artefatti evidenti.
Per esplorare l’applicazione dei modelli linguistici nella generazione di video, Google Research ha presentato VideoPoet, un modello linguistico di grandi dimensioni (LLM) in grado di eseguire un’ampia gamma di compiti di generazione di video, tra cui text-to-video, image-to-video, video stylization, video inpainting e outpainting e video-to-audio.
Un’osservazione degna di nota – sottolineano i ricercatori di Google – è che i principali modelli di generazione video sono quasi esclusivamente basati sulla diffusione (ad esempio, Imagen Video). D’altra parte, gli LLM sono ampiamente riconosciuti come lo standard de facto, grazie alle loro eccezionali capacità di apprendimento in varie modalità, tra cui il linguaggio, il codice e l’audio (ad esempio, AudioPaLM). A differenza dei modelli alternativi in questo spazio, l’approccio di Google Research integra perfettamente molte capacità di generazione video all’interno di un singolo LLM, invece di affidarsi a componenti addestrati separatamente e specializzati per ogni task.
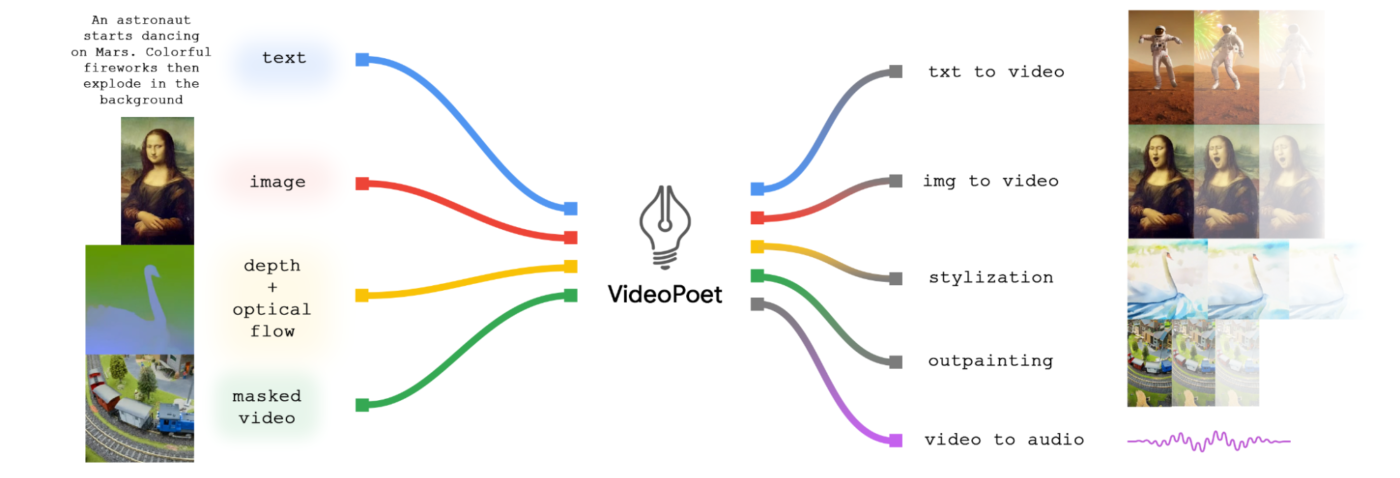
In VideoPoet di Google Research, le immagini in input possono essere animate per produrre il movimento e il video (opzionalmente ritagliato o mascherato) può essere modificato per l’inpainting o l’outpainting. Per la stilizzazione, il modello prende un video che rappresenta la profondità e il flusso ottico, che rappresentano il movimento, e dipinge i contenuti per produrre lo stile guidato dal testo.
Un vantaggio fondamentale dell’uso degli LLM per l’addestramento – afferma il team di ricerca – è che si possono riutilizzare molti dei miglioramenti di efficienza scalabili introdotti nelle infrastrutture di training LLM esistenti. Tuttavia, gli LLM operano su token discreti, il che può rendere difficile la generazione di video. Fortunatamente, mettono in evidenza i ricercatori, esistono tokenizer video e audio, che servono a codificare clip video e audio come sequenze di token discreti (cioè, indici interi), e che possono anche essere convertiti di nuovo nella rappresentazione originale.
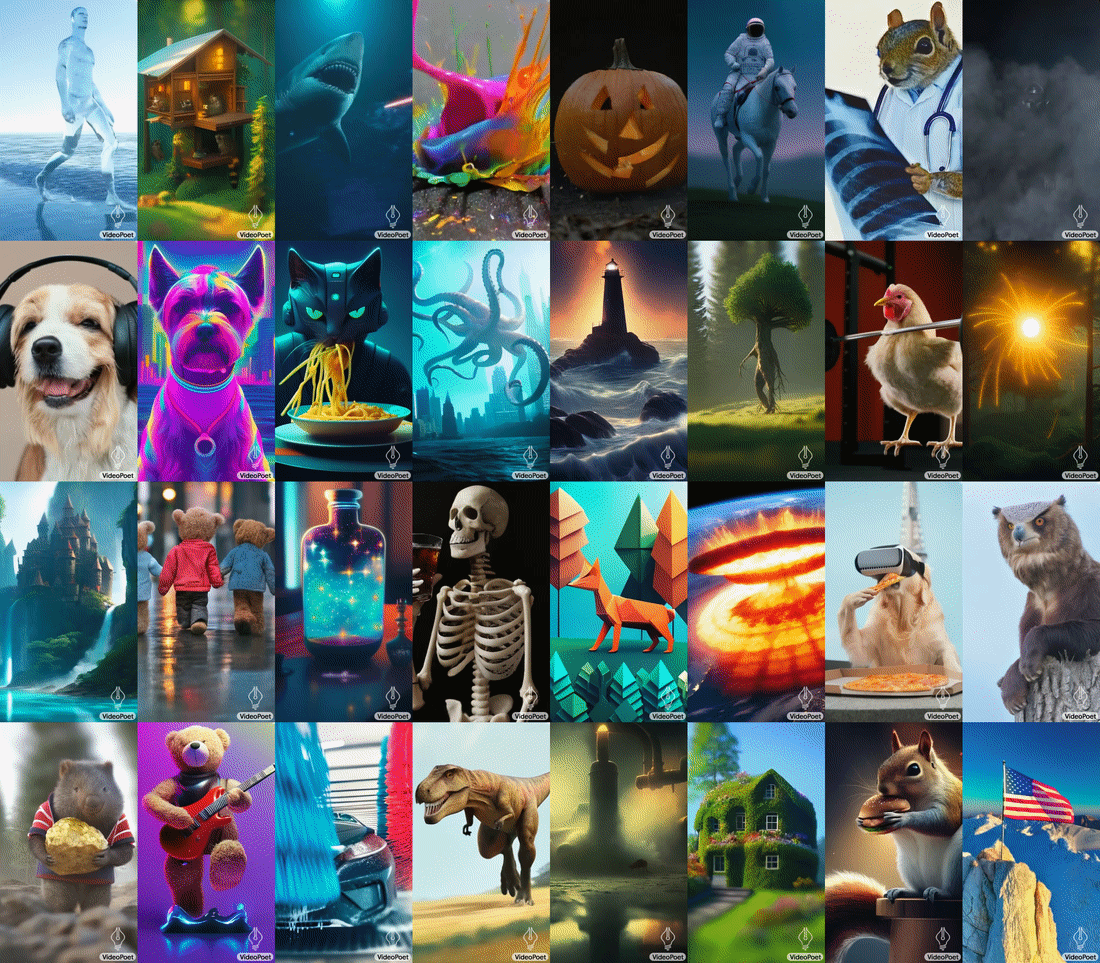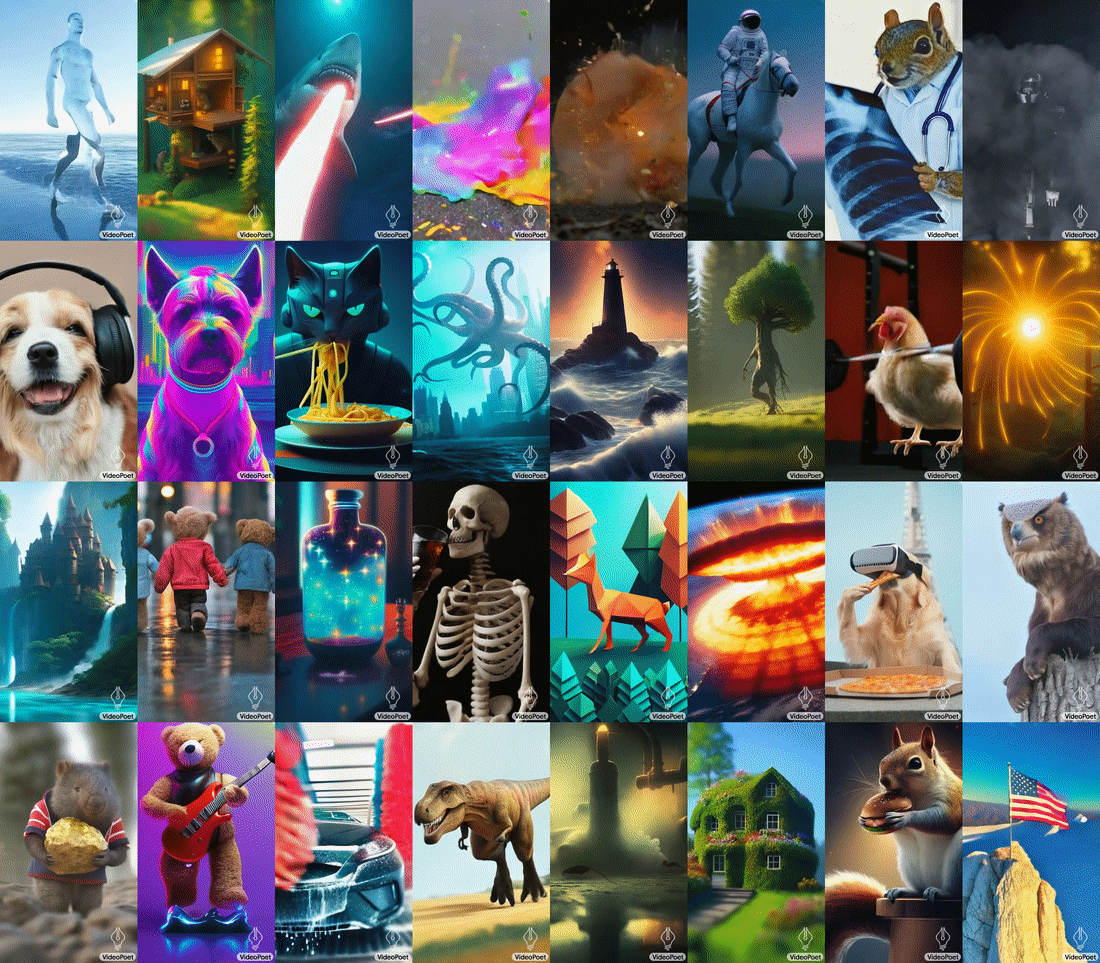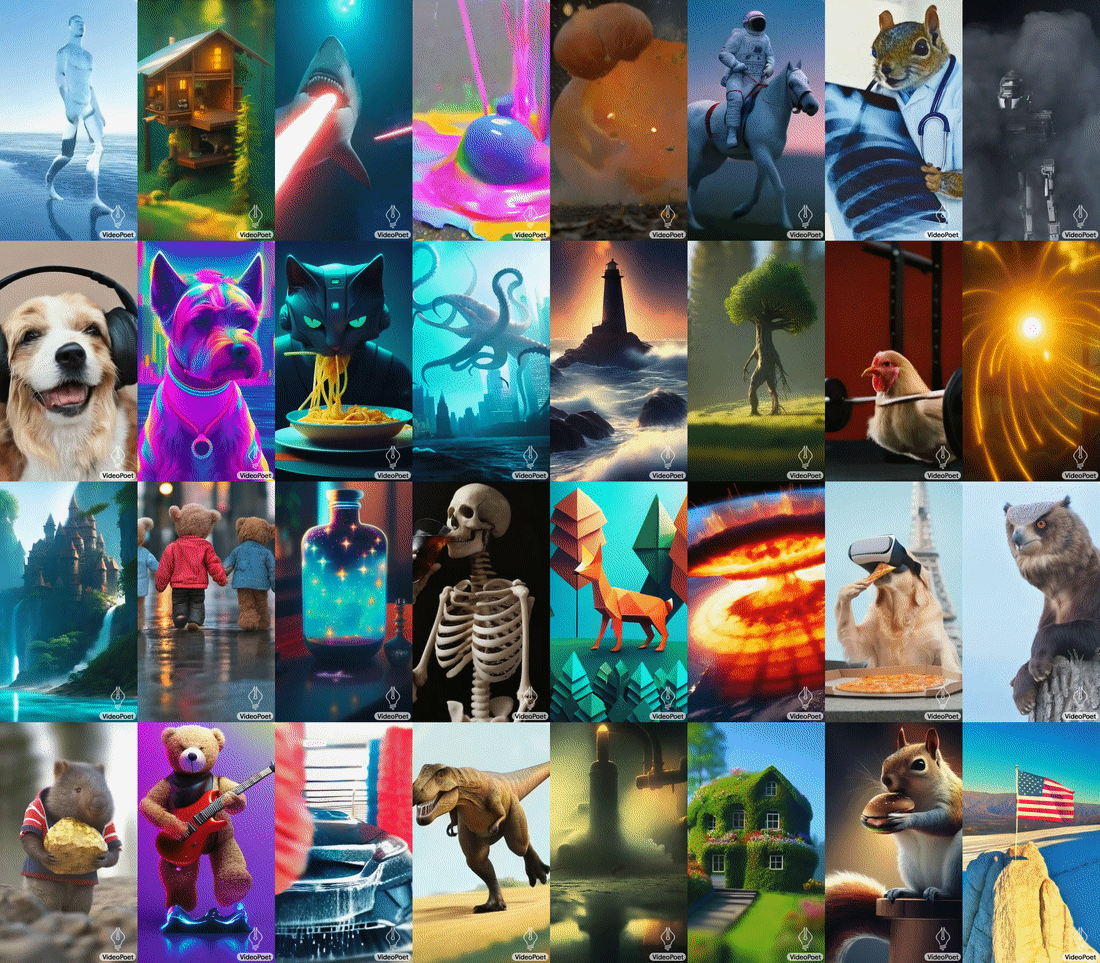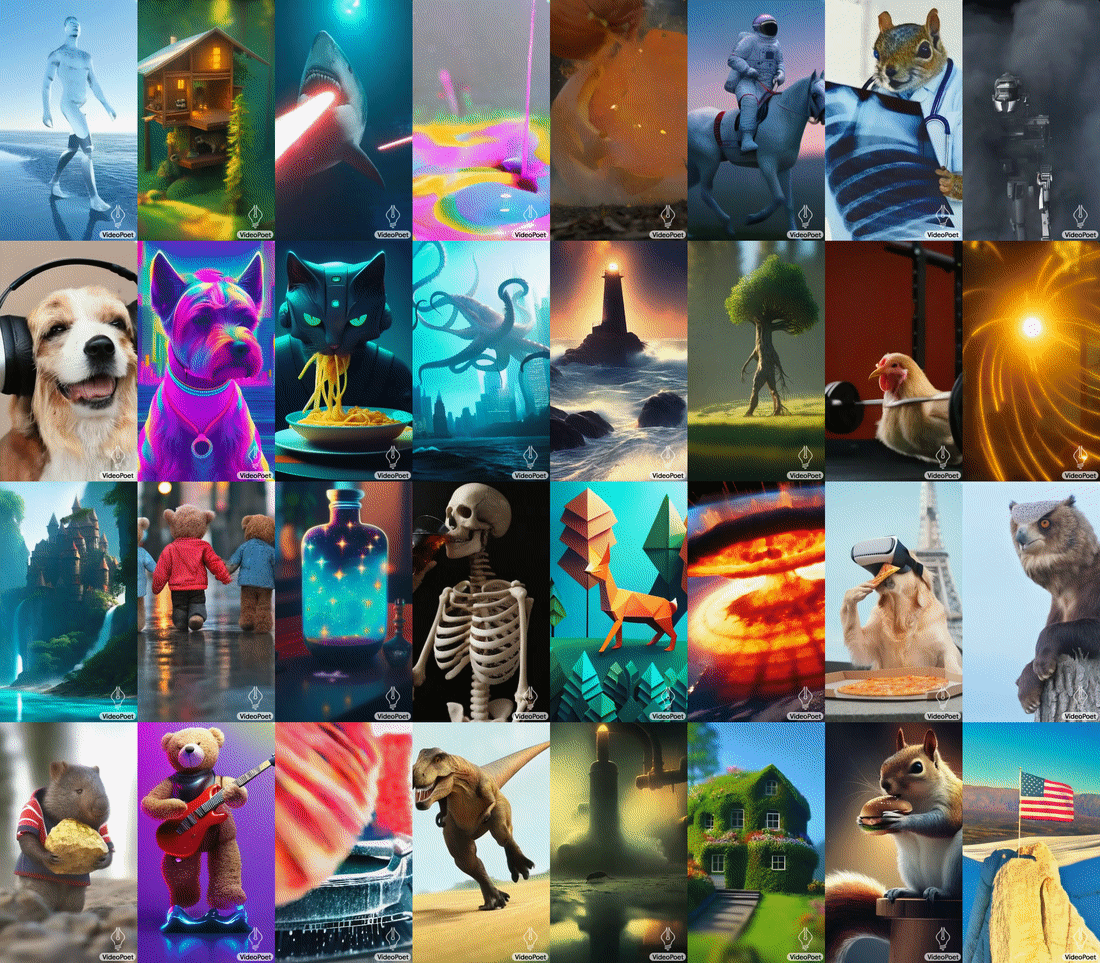
VideoPoet addestra un modello linguistico autoregressivo per apprendere le modalità video, immagine, audio e testo attraverso l’uso di più tokenizer (MAGVIT V2 per video e immagine e SoundStream per l’audio). Una volta che il modello genera token condizionati da un certo contesto, questi possono essere convertiti in una rappresentazione visualizzabile con i decoder tokenizer.
Per il text-to-video, spiega ancora Google Research, i risultati video sono di lunghezza variabile e possono applicare una serie di movimenti e stili a seconda del contenuto del testo.
Per l’image-to-video, VideoPoet può prendere l’immagine in input e animarla con un prompt. Per la stilizzazione dei video, vengono previste le informazioni sul flusso ottico e sulla profondità prima di inserirle in VideoPoet con un testo di input aggiuntivo.

VideoPoet è anche in grado di generare audio, con la possibilità anche di prevedere l’audio senza alcuna guida testuale. Ciò consente di generare video e audio da un unico modello.
Per impostazione predefinita, il modello VideoPoet genera video con orientamento verticale, per adattare il suo output a contenuti di breve durata. Per mostrare le sue capacità, Google Research ha prodotto un breve filmato composto da molte brevi clip generate da VideoPoet. Per la sceneggiatura, i ricercatori hanno chiesto a Bard di scrivere una breve storia su un procione viaggiatore, con una suddivisione scena per scena e un elenco di prompt ad accompagnarle. Hanno poi generato clip video per ciascun prompt e hanno unito tutte le clip risultanti per produrre il video finale.

I ricercatori hanno messo in evidenza alcune capacità notevoli del modello. Sono stati in grado di generare video più lunghi semplicemente condizionando l’ultimo secondo del video e prevedendo un secondo successivo, dimostrando, con una serie di ripetizioni, che il modello non solo è in grado di estendere bene il video, ma anche di preservare fedelmente l’aspetto di tutti gli oggetti anche per diverse iterazioni.
È anche possibile – sottolinea Google Research – modificare in modo interattivo i video clip esistenti generati da VideoPoet. Se si fornisce un video di input, si può modificare il movimento degli oggetti per eseguire diverse azioni. La manipolazione degli oggetti può essere centrata sul primo fotogramma o sui fotogrammi centrali, il che consente un elevato grado di controllo dell’editing. Ad esempio, è possibile generare casualmente alcuni clip dal video di input e selezionare il clip successivo desiderato.
Allo stesso modo, si può applicare il movimento a un’immagine in input per modificarne il contenuto verso lo stato desiderato, condizionato da un prompt di testo.

Ed è possibile anche controllare con precisione i movimenti della telecamera aggiungendo al prompt testuale il tipo di movimento desiderato. A titolo di esempio, il nostro modello ha generato un’immagine con la richiesta “concept art di un gioco d’avventura con un’alba su una montagna innevata vicino a un fiume cristallino”. Gli esempi che seguono aggiungono il suffisso al testo per applicare il movimento desiderato.
Secondo Google Research, attraverso VideoPoet il team ha dimostrato la qualità altamente competitiva dei modelli LLM nella generazione di video in un’ampia gamma di compiti, in particolare nella produzione di movimenti interessanti e di alta qualità all’interno dei video. I risultati suggeriscono il promettente potenziale degli LLM nel campo della generazione video. Per quanto riguarda le direzioni future, il framework dovrebbe essere in grado di supportare la generazione “any-to-any”, ad esempio estendendola a text-to-audio, audio-to-video e video captioning, tra le altre cose, sottolinea Google Research.
È possibile conoscere ulteriori dettagli e visualizzare diversi esempi in qualità originale, sul sito web dimostrativo di VideoPoet.